 Октябрь 2nd, 2017
Октябрь 2nd, 2017  Evgeniy Kamenev
Evgeniy Kamenev Описание AWK было взято из книги
Linux.Администрирование и системное проrраммирование 2-е издание. Марк Г.Собель
AWK является языком сканирования и обработки данных с помощью шаблонов,
позволяющим вести поиск записей (в качестве которых обычно выступают строки),
соответствующих указанным шаблонам, в одном или нескольких файлах. При обработке строк выполняются такие действия, как запись строк в стандартный вывод
или приращение значения счетчика при каждом обнаружении соответствия шаблону.
В отличие от процедурных языков, AWK является языком, управляемым данными: ему
предоставляется описание данных для обработки и сообщается, что нужно делать
с этими данными в случае их обнаружения.
AWK можно использовать для составления отчетов или для фильтрации текста.
Он одинаково хорошо работает как с числами, так и с текстами. AWK обычно дает
правильный результат и при работе со смешанными числовыми и текстовыми дан-
ными. Авторы AWK (а этот язык назван аббревиатурой, образованной от фамилий
авторов — Alfred V. Aho, Peter J. Weinberger, Brian W. Kernighan) разработали свое
детище с расчетом на простоту его использования. Для этого в исходной реализации
они сознательно пожертвовали скоростью работы.
AWK перенял многие конструкции у языка программирования C и обладает следующими свойствами:
|
1 2 3 4 5 6 7 8 9 10 |
Гибким форматом. Условным выполнением. Инструкциями цикла. Числовыми переменными. Строковыми переменными. Регулярными выражениями. Выражениями отношений. Такой же, как у C, функцией printf. Работой в режиме использования сопроцесса (только в gawk). Обменом данными по сети (только в gawk). |
Синтаксис
В командной строке gawk используется следующий синтаксис:
|
1 2 |
gawk [ключи] [программа] [список_файлов] gawk [ключи] –f файл_программы [список_файлов] |
Утилита gawk получает ввод из файлов, указанных в командной строке, или из стандартного ввода.
Аргументы
В приведенном выше примере синтаксиса программа — это программа на gawk, включаемая в командную строку.
Файл_программы — это имя файла, в котором содержится программа на gawk.
Включение программы в командную строку дает возможность писать короткие gawk-программы, не создавая отдельного файл_программы.
Чтобы оболочка не интерпретировала команды gawk как команды оболочки, программу
нужно поместить в одинарные кавычки.
Если поместить длинную или сложную программу в файл, это позволит сократить количество возможных ошибок и исключить повторный набор программы.
Список_файлов содержит путевые имена обычных файлов, обрабатываемых с помощью gawk.
Эти файлы являются файлами ввода. Если список_файлов не указан, gawk получает ввод из стандартного ввода или из источника,указанного в инструкции getline
Ключи
С ключами, перед которыми ставится двойной дефис (—), работает только утилита
gawk. При работе с awk или mawk эти ключи недоступны.
|
1 2 |
--field-separator fs -F fs |
Использование fs в качестве значения разделителя полей (field separator) ввода
|
1 2 |
--file файл_программы -f файл_программы |
Чтение gawk-программы из файла по имени файл_программы, а не из командной
строки. Этот ключ можно указать в командной строке более одного раза.
|
1 |
--help -W help |
Краткая справка по использованию gawk (только в gawk).
|
1 |
--lint -W lint |
Предупреждение о потенциально ошибочных или непереносимых конструктивных элементах gawk (только в gawk).
|
1 |
--posix -W posix |
Запуск POSIX-совместимой версии gawk. Этот ключ накладывает ряд ограничений, подробности которых даны в man-странице, посвященной gawk (тольков gawk).
|
1 |
--traditional -W traditional |
Игнорирование в gawk-программе новых функций GNU, позволяющее получить
программу, совместимую с UNIX awk (только в gawk).
|
1 2 |
--assign переменная=значение -v переменная=значение |
Присваивание значения переменной. Присваивание осуществляется еще до выполнения gawk-программы и доступно внутри шаблона BEGIN.
Этот ключ можно указать в командной строке более одного раза.
Основы языка
Программа на gawk (программа, набранная в командной строке или в файле_программы) состоит из одной и более строк, в которых содержится шаблон и (или) действие в следующем формате:
|
1 |
шаблон { действие } |
Шаблон выбирает строки из ввода. Утилита gawk выполняет действие над всеми строками, выбранными шаблоном.
Фигурные скобки, в которые заключено действие, позволяют gawk отличить его от шаблона. Если программная строка не содержит шаблона, gawk выбирает из ввода все строки.
Если программная строка не содержит действия, gawk копирует выбранные строки на стандартный вывод.
Сначала gawk сравнивает первую строку ввода (из файла, принадлежащего списку_файлов или из стандартного ввода) с каждым шаблоном программы.
Если шаблон выбирает строку (если определяется ее соответствие шаблону), gawk выполняет действие, связанное с этим шаблоном. Если строка не выбрана, gawk не выполняет действие.
Когда gawk завершит сравнение первой строки ввода, он повторяет процесс для следующей строки ввода. Он продолжает этот процесс сравнения последовательных
строк ввода, пока не прочитает весь ввод.
Если несколько шаблонов выбирают одну и ту же строку, gawk выполняет действие, связанное с каждым шаблоном, в порядке его появления в программе.
Утилита gawk может отправить на стандартный вывод одну и ту же строку ввода более одного раза.
Шаблоны
|
1 |
~ и !~ |
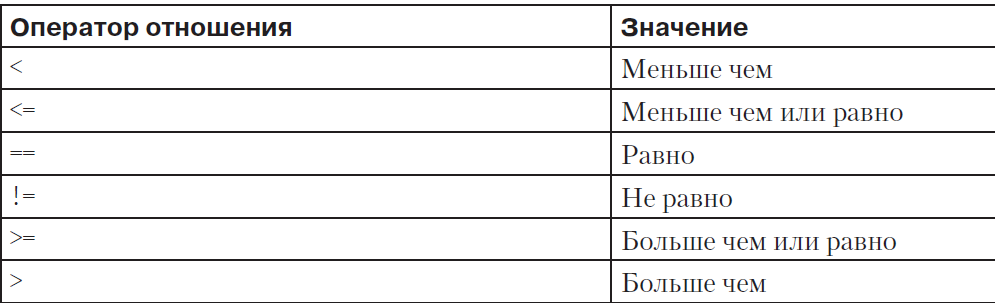
В качестве шаблона можно использовать регулярное выражение, заключенное в слэши. Оператор ~ проверяет, соответствует ли поле или переменная регулярному выражению.
Оператор !~ проводит проверку на несоответствие. Используя операторы отношений,
перечисленные в табл ниже, можно проводить как числовое, так и строковое сравнение.
Булевые операторы || (ИЛИ) и && (И) позволяют объединять любые шаблоны.
|
1 |
BEGIN и END |
Два уникальных шаблона, BEGIN и END, выполняют команды перед тем,
как утилита gawk приступит к обработке ввода, и после того, как она завершит эту обработку. До начала обработки всего ввода утилита gawk выполняет действия, связанные
с шаблоном BEGIN, а по окончании обработки — действия, связанные с шаблоном END
|
1 |
, (запятая) |
Запятая является оператором диапазона. Если два шаблона на одной
строке gawk‑программы разделены запятой, gawk выбирает диапазон строк, начиная
с первой строки, соответствующей первому шаблону. Последней строкой, выбранной
gawk, будет следующая строка из последовательности строк, соответствующая второму шаблону. Если второму шаблону не будет соответствовать ни одна строка, gawk
выберет каждую строку до конца ввода. После того как утилита gawk обнаружит соответствие второму шаблону, она возобновляет этот процесс, начиная новый поиск
соответствия первому шаблону.
Действия
Действие является частью команды gawk, заставляющее gawk выполнить это действие при обнаружении соответствия шаблону.
Если действие не указано, gawk выполняет действие по умолчанию.
В этом качестве используется команда print (которая в явном виде предоставляется как {print}). Это действие копирует запись (как правило, строку) из ввода в стандартный вывод.
Когда за командой print указываются аргументы, gawk выводит только их значения.
Аргументами могут быть переменные или строковые константы. Вывод команды print
можно отправить в файл (используя в gawk-программе символ >), добавить его к файлу (>>) или отправить через канал на ввод другой программы (|). Сопроцесс (|&) является двунаправленным каналом, осуществляющим обмен данными с программой, запущенной в фоновом режиме (доступен только в gawk)
Пока объекты в команде print не будут разделены запятыми, gawk проводит их объединение.
Запятые заставляют gawk разделить объекты, используя разделитель полей в выводе (OFS; как правило, в качестве разделителя используется пробел)
В одну строку могут быть включены несколько действий, разделенные точками с запятой.
Комментарии
Утилита gawk игнорирует ту часть программной строки, которая следует за знаком решетки (#).
Предваряя комментарии этим символом, можно осуществлять документирование gawk-программы.
Переменные
Хотя объявлять переменные в gawk до их применения не требуется, при желании им
можно присваивать начальные значения. Беззнаковые числовые переменные инициализируются значением 0; строковые переменные инициализируются пустой строкой.
Кроме поддержки пользовательских переменных, gawk поддерживает программные переменные.
Оба этих вида переменных (пользовательские и программные) можно использовать в тех частях gawk-программы, которые относятся к шаблонам и действиям.
Некоторые программные переменные перечислены в таблице ниже

Кроме инициализации переменных внутри программы для их инициализации
в командной строке можно воспользоваться ключом ––assign (–v).
Эта возможность пригодится в том случае, если значение переменной от запуска к запуску gawk изменяется.
Разделители Записей
По умолчанию записи во вводе и в выводе отделяются друг от друга разделителем строк.
То есть gawk принимает каждую строку ввода за отдельную запись и добавляет к концу каждой записи в выводе разделитель строк.
По умолчанию разделителями полей во вводе являются символы пробелов и табуляции, а в качестве разделителя полей в выводе используется пробел.
Значение любого разделителя можно в любое время заменить новым значением, присвоив это значение переменной либо из программы,
либо из командной строки с помощью ключа ––assign (–v).
Функции
В таблице ниже перечислены некоторые функции, предоставляемые gawk для работы с числами и строками.

Арифметические операторы
Арифметические операторы gawk, перечисленные в таблице ниже позаимствованы из языка C.
![]()


Ассоциативные массивы
Ассоциативный массив — одно из самых мощных средств gawk. В качестве индексов в этих массивах используются строки
Использование в качестве индексов числовых строк позволяет имитировать обычный массив.
Для присваивания значения элементу ассоциативного массива используется следующий синтаксис:
|
1 |
массив[строка] = значение |
где массив — это имя массива, строка — индекс элемента массива, которому присваивается значение, а значение — это значение, которое присваивается данному элементу.
Используя следующий синтаксис, при работе с ассоциативным массивом можно использовать управляющую структуру:
|
1 |
for (элемент in массив) действие |
где элемент — это переменная, которая принимает значение каждого элемента массива в процессе последовательного перебора элементов,
осуществляемого циклом, массив — имя массива, а действие — это действие, которое gawk выполняет в отношении каждого
элемента массива. В этом действии можно использовать переменную элемент.
printf
Для управления форматом вывода, генерируемого gawk, вместо команды print можно использовать команду printf.
Версия printf, используемая в gawk, похожа на одноименную функцию языка C. Команда printf использует следующий синтаксис:
|
1 |
printf "управляющая_строка",арг1, арг2, …, аргn |
Управляющая_строка определяет, как именно printf форматирует арг1, арг2, …, аргn.
Эти аргументы могут быть переменными или другими выражениями. Внутри управ-
ляющей_строки можно использовать символы \n для обозначения разделителя строк
и \t для обозначения символа TAB.
Управляющая_строка содержит спецификации преобразования, по одной для каждого аргумента.
Для спецификации преобразования используется следующий синтаксис:
|
1 |
%[–][x[.y]]conv |
где символ дефиса (–) заставляет printf выровнять аргумент по левому краю, x — это
минимальная ширина поля, а .y — количество знакомест в числе справа от десятичной
точки. Элемент conv обозначает тип числового преобразования и может быть выбран
из букв, показанных в таблице ниже.

Управляющие структуры
Управляющие (изменяющие ход программы) инструкции изменяют порядок выполнения команд в gawk-программе. В этом разделе рассматриваются подробности управляющих структур
if…else, while и for
Кроме этого рассматриваются инструкции breakи continue, которые используются в управляющих структурах для изменения порядка выполнения команд.
При указании одной простой команды использовать вокруг нее фигурные скобки необязательно.
Управляющая структура if…else
Управляющая структура if…else проверяет состояние, возвращенное условием, и передает управление на основе этого состояния.
В показанном ниже синтаксисе структуры if…else часть else является необязательной.
|
1 2 3 4 |
if (условие) {команды} [else {команды}] |
В простой, показанной здесь инструкции if фигурные скобки не используются:
|
1 |
if ($5 <= 5000) print $0 |
Следующая gawk-программа использует простую структуру if…else. Здесь фигур-
ные скобки также не используются.
|
1 |
# cat if1 |
|
1 2 3 4 5 6 7 |
BEGIN { nam="sam" if (nam == "max") print "nam is max" else print "nam is not max, it is", sam } |
|
1 |
# gawk -f if1 |
|
1 |
nam is not max, it is sam |
Управляющая структура while
Структура while осуществляет циклический проход и выполнение команд до тех пор, пока условие вычисляется в true.
Для структуры while используется следующий синтаксис:
|
1 2 |
while (условие) {команды} |
Следующая gawk-программа использует простую структуру while для вывода степеней числа два.
В этом примере используются фигурные скобки, потому что цикл while состоит из более чем одной инструкции.
Эта программа не получает ввода, и вся обработка проводится при выполнении gawk инструкций, связанных с шаблоном BEGIN.
|
1 |
# cat while1 |
|
1 2 3 4 5 6 7 8 |
BEGIN{ n = 1 while (n <= 5) { print "2^" n, 2**n n++ } } |
|
1 |
# gawk -f while1 |
|
1 2 3 4 5 |
2^1 2 2^2 4 2^3 8 2^4 16 2^5 32 |
Управляющая структура for
Для управляющей структуры for используется следующий синтаксис:
|
1 2 |
for (инициализация;условие; инкремент) {команды} |
Структура for начинает свою работу с выполнения инструкции инициализации, которая обычно устанавливает значение счетчика в 0 или 1.
Затем она выполняет циклический проход команд до тех пор, пока условие вычисляется в true.
После каждого цикла структура выполняет инструкцию инкремент. Gawk-программа for1 делает то же самое, что и предыдущая команда while1, с той лишь разницей, что в ней используется
инструкция for, упрощающая код программы:
|
1 |
# cat for1 |
|
1 2 3 4 |
BEGIN { for (n=1; n <= 5; n++) print "2^" n, 2**n } |
|
1 |
# gawk -f for1 |
|
1 2 3 4 5 |
2^1 2 2^2 4 2^3 8 2^4 16 2^5 32 |
Инструкция break
Инструкция break передает управление за пределы цикла for или цикла while, прерывая
выполнение цикла, внутри которого она присутствует.
Инструкция continue
Инструкция continue передает управление в конец цикла for или цикла while, приводя
к тому, что цикл, в котором она присутствует, продолжается со следующей итерации.
Полезные команды AWK
Вывод первого и четвертого поля, разделенных символом пробела
|
1 |
# awk -F":" '{print $1,$4}' /etc/passwd |
Или
|
1 |
# awk -F":" '{print $1 " " $4}' /etc/passwd |
|
1 |
# awk 'BEGIN{FS=":"} {print $1,$4}' /etc/passwd |
Вывод всех полей
|
1 |
# awk '{print $0}' /etc/passwd |
Добвавление в конце каждой строки символа ***
|
1 |
# awk '{print $0,"***"}' cars.txt |
Вывод первого и четвертого поля, разделенных символом табуляции
|
1 |
# awk -F":" '{print $1 "\t " $4}' /etc/passwd |
Вывод первого и шестого полей строк, со вхождением шаблона root
|
1 |
# awk -F":" '/root/ {print $1,$6}' /etc/passwd |
Вывод первого и шестого полей всех строк, в которых нет вхождения шаблона root
|
1 |
# awk -F":" '!/root/ {print $1,$6}' /etc/passwd |
Вывод первого и шестого полей всех строк, в которых есть вхождения шаблона root или шаблона ssh
|
1 |
# awk -F":" '/root/||/ssh/ {print $1,$6}' /etc/passwd |
Вывод первого поля(имени пользователя) у которого седьмое поле(оболочка) содержит шаблон bash
|
1 |
# awk -F":" '$7 ~/bash/ {print $1}' /etc/passwd |
Вывод первого поля(имени пользователя) у которого седьмое поле(оболочка) НЕ содержит шаблон bash
|
1 |
# awk -F":" '$7 !~/bash/ {print $1}' /etc/passwd |
Вывод строк, у которых последнее поле равно шаблону /bin/bash
|
1 |
# awk -F: '$NF=="/bin/bash" {print}' /etc/passwd |
Вывод строк совпадающих с шаблоном (аналог команды grep)
|
1 |
# awk '/root/' /etc/passwd |
Вывод всех строк,содержащих в первом поле шаблон ho
|
1 |
# awk '$1 ~ /ho/' cars.txt |
Вывод всех строк, содержащих в начале первого поля шаблон ho
|
1 |
# awk '$1 ~ /^ho/' cars.txt |
Вывод всех строк, которые не содержат в начале первого поля шаблон ho
|
1 |
# awk '$1 !~ /^ho/' cars.txt |
Вывод первого,третьего и шестого полей строк, у которых первого поле начинается на букву t или m
|
1 |
# awk '$1 ~ /^[tm]/ {print $1 $3 $6}' cars.txt |
Вывод третьего, первого полей, знака $ и пятого поля строк, в которых третье поле заканчивается на цифру 5
|
1 |
# awk '$3 ~ /5$/ {print $3, $1, "$" $5}' cars.txt |
Вывод строк, у которых третье поле равно 1985
|
1 |
# awk '$3 == 1985' cars.txt |
Вывод строк, у которых третье поле НЕ равно 1985
|
1 |
# awk '$3 != 1985' cars.txt |
Или
|
1 |
# awk '!($3 == 1985)' cars.txt |
Вывод строк, у которых третье поле меньше или равно 3000
|
1 |
# awk '$3<=3000' cars.txt |
Вывод строк, у которых пятое поле больше или равно 2000 и пятое поле меньше 9000 (используется логическое И)
|
1 |
# awk '$5 >= 2000 && $5 < 9000' cars.txt |
Вывод строк между двумя вхождениями(включая строки,содержащие эти вхождения)
|
1 |
# awk '/volvo/,/bmw/' cars.txt |
Вывод строк между двумя вхождениями шаблонов в первом поле
(включая строки,содержащие эти вхождения)
|
1 |
# awk '$1~"volvo", $1~"bmw"' cars.txt |
Вывод длины строки (без вывода строки)
|
1 |
# awk '{print length($0)}' cars.txt |
Вывод длины первого поля строки(без вывода поля/строки)
|
1 |
# awk '{print length($1)}' cars.txt |
Вывод длины строки и самой строки
|
1 |
# awk '{print length, $0}' cars.txt |
Вывод длины первого поля и первого поля
|
1 |
# awk '{print length($1),$1}' cars.txt |
Вывод номера строки, длина которой превышает 24 символа
|
1 |
# awk 'length > 24 {print NR}' cars.txt |
Вывод строк, длина которой превышает 24 символа
|
1 |
# awk 'length($0) > 24' cars.txt |
Или
|
1 |
# awk 'length > 24' cars.txt |
Вывод длины самой длинной строки
|
1 |
# awk '{ if (length($0) > max) max=length($0) } END {print max}' cars.txt |
Замена значения первого поля,в зависимости от изначального значение первого поля.
Если первое поле содержит шаблон ply, то присвоить первому полю значение plymouth
Если первое поле содержит шаблон chev, то присвоить первому полю значение chevrolet
Кроме этого использует ключ -f для получения инструкций из файла, что
полезно, когда их большое количество и вводить их вручную в терминале непрактично
|
1 |
# cat separ_demo |
|
1 2 3 4 5 |
{ if ($1 ~/ply/) $1 = "plymouth" if ($1 ~/chev/) $1 = "chevrolet" print } |
|
1 |
# awk -f separ_demo cars.txt |
Использование автономного сценария(вместо вызова awk из командной строки с ключом -f) ,запускающий ту же программу, что указана выше
|
1 |
# nano separ_demo2 |
|
1 2 3 4 5 6 |
#!/bin/awk -f { if ($1 ~ /ply/) $1 = "plymouth" if ($1 ~ /chev/) $1 = "chevrolet" print } |
|
1 |
# chmod u+rx separ_demo2 |
|
1 |
# ./separ_demo2 cars.txt |
Замена разделителя полей в выводе на символ табуляции(по умолчанию используется пробел)
|
1 2 3 4 5 6 7 |
#!/bin/awk -f BEGIN {OFS = "\t"} { if ($1 ~ /ply/) $1 = "plymouth" if ($1 ~ /chev/) $1 = "chevrolet" print } |
|
1 |
# ./separ_demo2 cars.txt |
Создание отдельных файлов со строками,которые содержат шаблоны chevy и ford
|
1 |
# nano redirect_out |
|
1 2 3 |
/chevy/ {print > "chevyfile"} /ford/ {print > "fordfile"} END {print "Ready"} |
|
1 |
# awk -f redirect_out cars.txt |
Запись второго поля всех строк в отдельный файл
|
1 |
# awk '{print $2 > "newfile.txt"}' cars.txt |
Изменения дефолтного разделитя(пробел) полей в выводе на символ =>
|
1 |
# awk -F: 'BEGIN {OFS="=>"} {print $1,$4}' /etc/passwd |
Вывод всех строк начиная с 5-й строки и до конца файла
|
1 |
# awk 'NR>=5' cars.txt |
Вывод первых десяти строк файла(аналог команды head)
|
1 |
# awk 'NR < 11' cars.txt |
Вывод первой строки файла (аналог команды head -1)
|
1 |
# awk 'NR>1{exit} {print}' cars.txt |
Вывод двух последних строк файла (аналог команды tail -2)
|
1 |
# awk '{y=x "\n" $0; x=$0};END{print y}' cars.txt |
Вывод последней строки файла (аналог команды tail -1)
|
1 |
# awk 'END{print}' cars.txt |
Вывод строк,содержащих шаблон (аналог команды grep)
|
1 |
# awk '/ford/ {print}' cars.txt |
Вывод строк, НЕ содержащих шаблон (аналог команды grep -v)
|
1 |
# awk '!/ford/ {print}' cars.txt |
Вывод строки,которая предшествует строке,содержащей шаблон(при этом строка,содержащая шаблон не выводится
|
1 |
# awk '/regexp/{print x};{x=$0}' cars.txt |
Вывод строки,которая находится после строки, содержащей шаблон(при этом строка, содержащая шаблон не выводится
|
1 |
# awk '/regexp/{getline;print}' cars.txt |
Вывод строк,содержащих указанные шаблоны в одной строке(в любом порядке)
|
1 |
# awk '/AAA/ && /BBB/ && /CCC/' cars.txt |
Вывод строк,содержащих указанные шаблоны в одной строке(в строго указанном порядке)
|
1 |
# awk '/AAA.*BBB.*CCC/' cars.txt |
Вывод всех строк начиная со строки, содержащей регулярное выражение и до конца файла
|
1 |
# awk '/regexp/,0' cars.txt |
Или
|
1 |
# awk '/regexp/,EOF' cars.txt |
Вывод строк с 5-ой по 10-ю
|
1 |
# awk 'NR==5,NR==10' cars.txt |
Вывод 12-ой строки
|
1 |
# awk 'NR==12' cars.txt |
Или (более эффективно для больших файлов)
|
1 |
# awk 'NR==12 {print;exit}' cars.txt |
Вывод номера строки перед самой строкой
|
1 |
# awk '$0 = NR" "$0' cars.txt |
Или
|
1 |
# awk '{print FNR " " $0}' cars.txt |
Вывод строк с кол-вом полей больше или равно 5
|
1 |
# awk 'NF >= 5' cars.txt |
Вывод строк, у которых значение последнего поля больше 4
|
1 |
# awk '$NF > 4' cars.txt |
Вывод последнего поля всех строк
|
1 |
# awk '{print $NF}' cars.txt |
Вывод последнего поля последней строки
|
1 |
# awk '{ print NF ":" $0 }' cars.txt |
Вывод предпоследнего поля всех строк
|
1 |
# awk '{print $(NF-1)}' cars.txt |
Вывод поля с середины всех строк
|
1 |
# awk '{print $(NF/2)}' cars.txt |
Вывод кол-ва строк
|
1 |
# awk 'END {print NR}' cars.txt |
Вывод четных строк файла
|
1 |
# awk 'NR % 2 == 0' cars.txt |
Удаление пустых строк файла
|
1 |
# awk NF cars.txt |
Или
|
1 |
# awk '/./' cars.txt |
Удаление пробелов/табуляции в начале каждой строки
|
1 |
# awk '{sub(/^[ \t]+/, "")};1' cars.txt |
Удаление пробелов/табуляции в конце каждой строки
|
1 |
# awk '{sub(/[ \t]+$/, "")};1' cars.txt |
Удаление пробелов/табуляции в начале и в конце каждой строки
|
1 |
# awk '{gsub(/^[ \t]+|[ \t]+$/,"")};1' cars.txt |
Вставка пяти символов пробела в начале каждой строки
|
1 |
# awk '{sub(/^/, " ")};1' cars.txt |
Вывод первых трех столбцов каждой строки по одному в строке
|
1 |
# awk '{ for (i=1; i<=3; i++) print $i }' cars.txt |
Изменения дефолтного разделитя(пробел или табуляция) полей в ввода
|
1 |
# awk -F":" '{print $1 " " $4}' /etc/passwd |
Или
|
1 |
# awk 'BEGIN{FS=":"} {print $1,$4}' /etc/passwd |
Вывод суммы значений третьих полей
|
1 |
# awk -F: '{sum +=$3} END {print sum}' /etc/passwd |
Вывод суммы всех полей для каждой строки
|
1 |
# awk '{s=0; for (i=1; i<=NF; i++) s=s+$i; print s}' cars.txt |
Вывод суммы всех полей всех строк
|
1 |
# awk '{for (i=1; i<=NF; i++) s=s+$i}; END{print s}' cars.txt |
Вывод общего кол-ва полей
|
1 |
# awk '{ total = total + NF }; END {print total}' cars.txt |
Вывод кол-ва строк,которые содержат шаблон honda
|
1 |
# awk '/honda/{n++}; END {print n+0}' cars.txt |
Источник:
Linux.Администрирование и системное проrраммирование 2-е издание. Марк Г.Собель
http://www.pement.org/awk/awk1line.txt
http://rus-linux.net/MyLDP/consol/awk.html
http://www.grymoire.com/Unix/Awk.html
 Опубликовано в рубрике
Опубликовано в рубрике  Метки:
Метки: