 Октябрь 24th, 2021
Октябрь 24th, 2021  Evgeniy Kamenev
Evgeniy Kamenev
Поднятие 3-х master-нод и 2-х worker-нод с автоматическим provisioning:
— всех необходимых настроек для подготовки нод к установке k8s-кластера
— установка Haproxy на master0{1..2}-нодах в качестве балансировщика нагрузки на транспортном уровне (Level 4)
а) балансировка входящих kube-api-запросов, поступающих от kubelet и других клиентов на все kube-api поды запущенные на master-нодах
б) балансировка входящих клиентских/пользовательских запросов на порт 80 на ingress-nginx поды, запущенные на worker-нодах
— установка keepalived на master0{1..2}-нодах в качестве реализации Linux Virtual Server(LVS) для работы с виртуальным/плавающим IP-адресом для kube-api и пользовательских-запроcов
Ручная установка k8s-кластера с помощью kubeadm на подготовленных Vagrant-ом виртуальных машинах
Структурная схема имеет вид
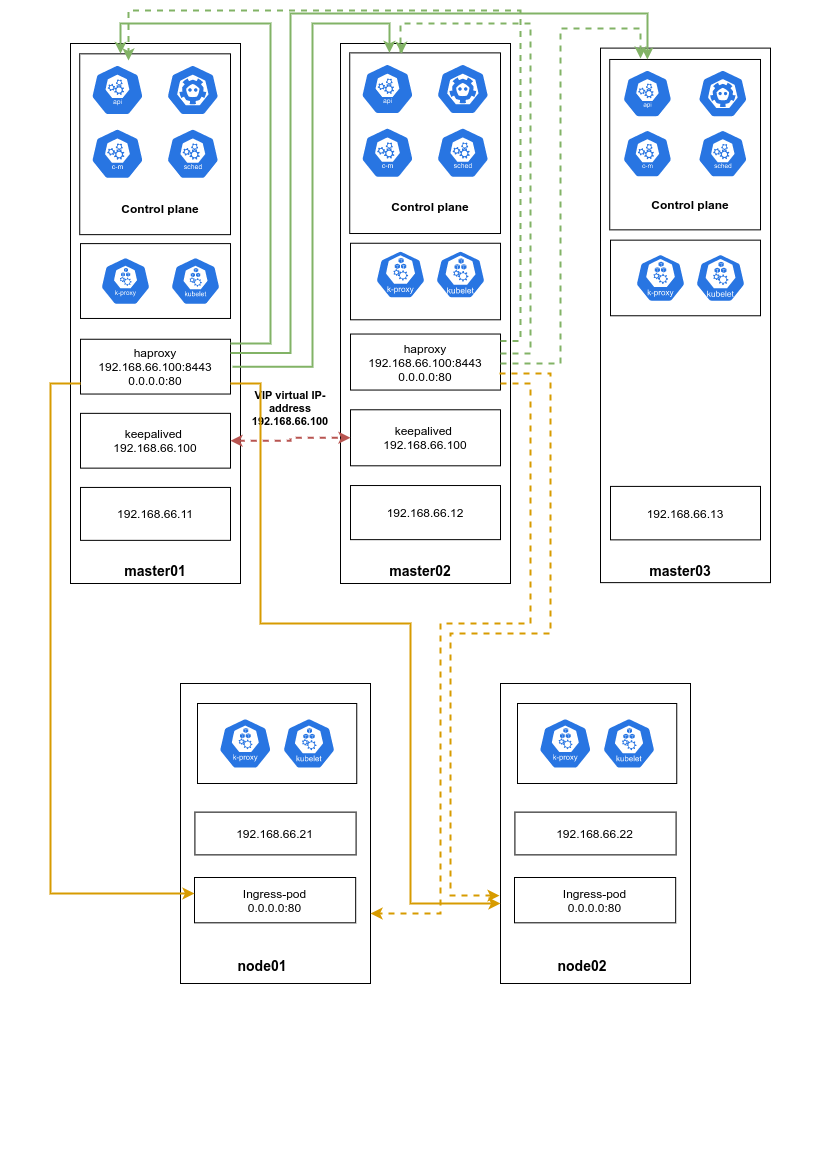
Репозитарий с vagrant-k8s доступен по адресу:
https://bitbucket.org/kamaok/vagrant-k8s/src/master/
В Vagrant-файле указаны версии пакетов/программного обеспечения, которое будет установлено
kubeadm,kubelet,kubectl - 1.21.2 (при инициализации кластера командой kubeadm используется соответствующая версия через указание опции --kubernetes-version "1.21.2")
containerd - 1.4.6
В качестве container runtime interface (CRI) по дефолту используется containerd если необходимо использовать docker в качестве CRI, тогда в Vagrantfile необходимо внести изменения:
— закомментировать провизионинг contanerd
|
1 2 3 |
node.vm.provision "setup-containerd", :type => "shell", :path => "centos/setup-containerd.sh" do |s| s.args = ["1.4.6"] end |
— раскомментировать провизионинг dockerd
|
1 |
node.vm.provision "setup-docker", :type => "shell", :path => "centos/setup-docker.sh" |
Соответствие имени и IP-адреса, которые добавлены в /etc/hosts на всех серверах
|
1 2 3 4 5 6 |
master05 - 192.168.66.11 master04 - 192.168.66.12 master03 - 192.168.66.13 node01 - 192.168.66.21 node02 - 192.168.66.22 loadbalancer - 192.168.66.100 |
Если необходимо добавить/удалить мастера/воркеры, тогда изменените соответствущие настройки/файлы
— в Vagrnatfile
|
1 2 |
NUM_MASTER_NODE = NUM_WORKER_NODE = |
в файле
|
1 |
centos/configure-etc-hosts.sh |
в файле
|
1 |
centos[78]/setup-haproxy.sh |
HAproxy web-интерфейс будет доступен в локальном браузере через URL:
http://localhost:61001 — для HAproxy, запущенного на master01
http://localhost:61002 — для HAproxy, запущенного на master02
Ingres-nginx, который запущен на worker-нодах в режиме
host network: true
или через host port
доступен в локальном браузере через URL:
http://localhost:8021 — для Ingres-nginx, запущенного на node01
http://localhost:8022 — для Ingres-nginx, запущенного на node02
Подготовка нод кластера
Активация Vagrant-файла для нужной версии Centos (7/8)
В данном случае для Centos 8
|
1 |
# ln -sf Vagrantfile-cluster-centos-8 Vagrantfile |
Проверка синтаксиса конфигурационого файла Vagrant
|
1 |
# vagrant validate |
Создание и автоматическая настройка всех нод кластера
|
1 |
# vagrant up |
Установка keepalived на master01
|
1 |
# sed -i 's|#node.vm.provision "setup-keepalived", type: "shell", :path => "centos/setup-keepalived-master01.sh|node.vm.provision "setup-keepalived", type: "shell", :path => "centos/setup-keepalived-master01.sh|' Vagrantfile |
|
1 |
# vagrant provision master01 --provision-with setup-keepalived |
Установка keepalived на master02
|
1 |
# sed -i 's|node.vm.provision "setup-keepalived", type: "shell", :path => "centos/setup-keepalived-master01.sh|#node.vm.provision "setup-keepalived", type: "shell", :path => "centos/setup-keepalived-master01.sh|' Vagrantfile |
|
1 |
# sed -i 's|#node.vm.provision "setup-keepalived", type: "shell", :path => "centos/setup-keepalived-master02.sh|node.vm.provision "setup-keepalived", type: "shell", :path => "centos/setup-keepalived-master02.sh|' Vagrantfile |
|
1 |
# vagrant provision master02 --provision-with setup-keepalived |
Отключим активированный предыдущей командой provisioning keepalived
|
1 |
# sed -i 's|node.vm.provision "setup-keepalived", type: "shell", :path => "centos/setup-keepalived-master02.sh|#node.vm.provision "setup-keepalived", type: "shell", :path => "centos/setup-keepalived-master02.sh|' Vagrantfile |
Проверка отработки всех provisioning-задач/скриптов: На master-ах(например, на master01)
|
1 |
# vagrant ssh test01 |
|
1 |
# sudo su -l |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
iptables -S free -mw getenforce cat /etc/hosts systemctl status containerd cat /etc/sysctl.d/k8s.conf lsmod | grep -E 'overlay|br_netfilter' kubelet --version kubeadm version kubectl version --client cat /etc/sysctl.d/k8s.conf systemctl status haproxy systemctl status keepalived netstat -nlptu | grep -E '8443|80' ip a sh | grep 192.168.66 |
На node-ах
|
1 |
# vagrant ssh node01 |
|
1 |
# sudo su -l |
|
1 2 3 4 5 6 7 8 9 10 11 |
iptables -S free -mw getenforce cat /etc/hosts systemctl status containerd cat /etc/sysctl.d/k8s.conf lsmod | grep -E 'overlay|br_netfilter' kubelet --version kubeadm version kubectl version --client cat /etc/sysctl.d/k8s.conf |
Инициализация кластера
https://v1-21.docs.kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm
https://v1-21.docs.kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability
При инициализации кластера командой kubeadm используе следующие опции/флаги:
|
1 2 3 4 5 |
--apiserver-advertise-address --control-plane-endpoint --kubernetes-version --pod-network-cidr --pod-network-cidr |
--apiserver-advertise-address "IP_ADDRESS_INTERFACE_FOR_NODE_COMMUNICATION"
В нашем случае --apiserver-advertise-address "192.168.66.11" IP-адрес, на котором api-сервер будет оповещать/уведомлять других членов кластера.
По дефолту виртуалка,созданная через наш Vagrantfile выходит в инет через интерфейс eth0, который имеет тип nat и настроен на динамическое получение сетевых настроек по dhcp с хоста вагранта
|
1 |
# ip r get 8.8.8.8 |
|
1 |
8.8.8.8 via 10.0.2.2 dev eth0 src 10.0.2.15 |
|
1 |
# ip a sh | grep -E 'eth[01]|lo:|inet ' |
|
1 2 3 4 5 6 |
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 inet 127.0.0.1/8 scope host lo 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 inet 10.0.2.15/24 brd 10.0.2.255 scope global noprefixroute dynamic eth0 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 inet 192.168.66.11/24 brd 192.168.66.255 scope global noprefixroute eth1 |
Нам же нужно,чтобы взаимодействие осуществлялось через подсеть 192.168.66.0/24 Поэтому принудительно указываем IP-адрес, который виртуалка имеет на интерфейса eth1, через который она будет общаться с другими компонентами и хостами k8s-кластере.
В нашем случае IP-адрес 192.168.66.11
|
1 |
# ip r get 192.168.66.1 |
|
1 |
local 192.168.66.1 dev eth1 src 192.168.66.11 |
--control-plane-endpoint "LOAD_BALANCER_DNS:LOAD_BALANCER_PORT"
--control-plane-endpoint — указываем имя лоадбалансера, на котором настроен виртуальный плавающий IP-адрес(192.168.66.100)
В нашем случае --control-plane-endpoint "loadbalancer:8443"
|
1 |
# grep loadbalancer /etc/hosts |
|
1 |
192.168.66.100 loadbalancer loadbalancer.local |
В нашем случае имя loadbalancer — 192.168.66.100(на всех хостах добавлена соотвествующая запиcь в /etc/hosts-файл)
Порт 8843 — это порт,который слушает Haproxy на master0{1..2}-нодах т.к. на master-ах также будет запущен kube-api сервер, который слушает по дефолту на порту 6443, то используем отличный от 6443 порт для прослушивания Haproxy запросов к нему --kubernetes-version — указываем конкретную версию Kubernetes, которую хотим установить.
Рекомендуется использовать такую же версию, как и версия kubeadm,kubelet,kubectl
В нашем случае 1.21.2 --kubernetes-version "1.21.2"
--upload-certs — загрузить сертификаты в k8s-секрет с именем kubeadm-certs в namespace kube-system, которые будут расшарены/подложены на все master-ноды кластера.
Этот секрет будет автоматически удален через 2 часа Альтернативным вариантом может быть ручное или автоматическиое с помощью систем управления конфигурациями подкладывание/копирование этих сертификатов на master-ноды.
Тогда этот флаг использовать не нужно
--pod-network-cidr — указываем подсеть, которая будет использоваться для подов
Эта подсеть будет разбита/разделена на подсети и такие подсети будут назанчены на все хосты(как master, так и worker) кластера
В качестве CNI(Container Network Interface) будем использовать Calico, который по умочанию использует подсеть 192.168.0.0/16
Во избежания совпадения подсетей между Calico и внутренней сети вагранта (192.168.66.0/24 в нашем случае)
Принудительно укажем подсеть, которую нужно использовать для подов при инициализации кластера через параметр --pod-network-cidr
При установке Calico, он будет учитывать,что нужно использовать подсеть, которую мы указали при инициализаици кластера и не будет использоват свою дефолтную подсеть Например, возьмем подсеть: 10.200.0.0/16
--pod-network-cidr "10.200.0.0/16"
Итого команда по инициализации кластера имеет вид
|
1 |
# kubeadm init --apiserver-advertise-address "192.168.66.11" --control-plane-endpoint "loadbalancer:8443" --kubernetes-version "1.21.2" --upload-certs --pod-network-cidr "10.200.0.0/16" |
Инициализация кластера
|
1 |
# vagrant ssh master01 |
|
1 |
# kubeadm init --apiserver-advertise-address "192.168.66.11" --control-plane-endpoint "loadbalancer:8443" --kubernetes-version "1.21.2" --upload-certs --pod-network-cidr "10.200.0.0/16" |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join loadbalancer:8443 --token kgo0n6.7b1hqnbk07i20vij \ --discovery-token-ca-cert-hash sha256:75be71dd534d9a29b30bb61bc642160048aee98b04f804866ed308695f821498 \ --control-plane --certificate-key 6b799c25419f077da2b23b02cf733fa67444986f5d2dfdb2ad1a785171f0fefb Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join loadbalancer:8443 --token kgo0n6.7b1hqnbk07i20vij \ --discovery-token-ca-cert-hash sha256:75be71dd534d9a29b30bb61bc642160048aee98b04f804866ed308695f821498 |
Настройка файла для аутентификации и авторизации в k8s для master01-ноды
|
1 |
# mkdir -p $HOME/.kube |
|
1 |
# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config |
|
1 |
# sudo chown $(id -u):$(id -g) $HOME/.kube/config |
|
1 |
# kubectl get pod -A |
|
1 2 3 4 5 6 7 8 |
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-558bd4d5db-dhj94 0/1 Pending 0 2m14s kube-system coredns-558bd4d5db-dvcrr 0/1 Pending 0 2m14s kube-system etcd-master01 1/1 Running 0 2m14s kube-system kube-apiserver-master01 1/1 Running 0 2m27s kube-system kube-controller-manager-master01 1/1 Running 0 2m14s kube-system kube-proxy-bxj4q 1/1 Running 0 2m14s kube-system kube-scheduler-master01 1/1 Running 0 2m14s |
Установка calico в качестве Container Network Interface
|
1 |
# curl -o /home/vagrant/calico.yaml https://docs.projectcalico.org/manifests/calico.yaml |
|
1 |
# kubectl apply -f /home/vagrant/calico.yaml |
|
1 |
# kubectl get pod -n kube-system |
|
1 2 3 4 5 6 7 8 9 10 |
NAME READY STATUS RESTARTS AGE calico-kube-controllers-78d6f96c7b-sctz9 1/1 Running 0 3m45s calico-node-kbfwb 1/1 Running 0 3m45s coredns-558bd4d5db-dhj94 1/1 Running 0 8m34s coredns-558bd4d5db-dvcrr 1/1 Running 0 8m34s etcd-master01 1/1 Running 0 8m34s kube-apiserver-master01 1/1 Running 0 8m47s kube-controller-manager-master01 1/1 Running 0 8m34s kube-proxy-bxj4q 1/1 Running 0 8m34s kube-scheduler-master01 1/1 Running 0 8m34s |
И только после того, как поднялись контейнеры с coredns и calico добавляем остальные мастера в кластер
Дополнительно к команде по добавлению ноды в кластер, я принудительно добавил параметр --apiserver-advertise-address со значением IP-адреса ноды, через который должно происходить взаимодействие с остальными членами кластера в нашем случае 192.168.66.12
Добавление второго мастера в k8s-кластер
|
1 |
# vagrant ssh master02 |
|
1 2 3 4 |
# kubeadm join loadbalancer:8443 --token kgo0n6.7b1hqnbk07i20vij \ --discovery-token-ca-cert-hash sha256:75be71dd534d9a29b30bb61bc642160048aee98b04f804866ed308695f821498 \ --control-plane --certificate-key 6b799c25419f077da2b23b02cf733fa67444986f5d2dfdb2ad1a785171f0fefb \ --apiserver-advertise-address "192.168.66.12" |
Настройка файла для аутентификации и авторизации в k8s для master02-ноды
|
1 |
# mkdir -p $HOME/.kube |
|
1 |
# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config |
|
1 |
# sudo chown $(id -u):$(id -g) $HOME/.kube/config |
Добавление третьего мастера в k8s-кластер
|
1 |
# vagrant ssh master03 |
|
1 2 3 4 |
# kubeadm join loadbalancer:8443 --token kgo0n6.7b1hqnbk07i20vij \ --discovery-token-ca-cert-hash sha256:75be71dd534d9a29b30bb61bc642160048aee98b04f804866ed308695f821498 \ --control-plane --certificate-key 6b799c25419f077da2b23b02cf733fa67444986f5d2dfdb2ad1a785171f0fefb \ --apiserver-advertise-address "192.168.66.13" |
Настройка файла для аутентификации и авторизации в k8s для master03-ноды
|
1 |
# mkdir -p $HOME/.kube |
|
1 |
# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config |
|
1 |
# sudo chown $(id -u):$(id -g) $HOME/.kube/config |
Добавление первой рабочей ноды в k8s-кластер
|
1 |
# vagrant ssh node01 |
|
1 2 |
# kubeadm join loadbalancer:8443 --token kgo0n6.7b1hqnbk07i20vij \ --discovery-token-ca-cert-hash sha256:75be71dd534d9a29b30bb61bc642160048aee98b04f804866ed308695f821498 |
Добавление второй рабочей ноды в k8s-кластер
|
1 |
# vagrant ssh node02 |
|
1 2 |
# kubeadm join loadbalancer:8443 --token kgo0n6.7b1hqnbk07i20vij \ --discovery-token-ca-cert-hash sha256:75be71dd534d9a29b30bb61bc642160048aee98b04f804866ed308695f821498 |
|
1 |
# kubectl get node |
|
1 2 3 4 5 6 |
NAME STATUS ROLES AGE VERSION master01 Ready control-plane,master 17m v1.21.2 master02 Ready control-plane,master 7m26s v1.21.2 master03 Ready control-plane,master 4m1s v1.21.2 node01 Ready 114s v1.21.2 node02 Ready 56s v1.21.2 |
|
1 |
# kubectl get pod -A |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-78d6f96c7b-8zhm9 1/1 Running 0 15m kube-system calico-node-7wrx5 1/1 Running 0 5m28s kube-system calico-node-9ppk4 1/1 Running 0 6m25s kube-system calico-node-p5tpb 1/1 Running 0 11m kube-system calico-node-t8n6q 1/1 Running 0 8m33s kube-system calico-node-zmb9x 1/1 Running 0 15m kube-system coredns-558bd4d5db-rx875 1/1 Running 0 21m kube-system coredns-558bd4d5db-vc26d 1/1 Running 0 21m kube-system etcd-master01 1/1 Running 0 21m kube-system etcd-master02 1/1 Running 0 11m kube-system etcd-master03 1/1 Running 0 8m30s kube-system kube-apiserver-master01 1/1 Running 0 21m kube-system kube-apiserver-master02 1/1 Running 0 11m kube-system kube-apiserver-master03 1/1 Running 0 8m31s kube-system kube-controller-manager-master01 1/1 Running 1 21m kube-system kube-controller-manager-master02 1/1 Running 0 11m kube-system kube-controller-manager-master03 1/1 Running 0 8m31s kube-system kube-proxy-24xkd 1/1 Running 0 8m33s kube-system kube-proxy-5bgpt 1/1 Running 0 6m25s kube-system kube-proxy-6ff2m 1/1 Running 0 11m kube-system kube-proxy-7f9zc 1/1 Running 0 5m28s kube-system kube-proxy-gfqk5 1/1 Running 0 21m kube-system kube-scheduler-master01 1/1 Running 1 21m kube-system kube-scheduler-master02 1/1 Running 0 11m kube-system kube-scheduler-master03 1/1 Running 0 8m31s |
После запуска master-ов проверяем поднятие всех мастеровых компонентов k8s включая haproxy
|
1 |
# netstat -nlptu | grep -E '6443|23[78][91]|8443|1025[0697]' |
|
1 2 3 4 5 6 7 8 9 10 |
tcp 0 0 127.0.0.1:8443 0.0.0.0:* LISTEN 4283/haproxy tcp 0 0 192.168.66.100:8443 0.0.0.0:* LISTEN 4283/haproxy tcp 0 0 192.168.66.11:2379 0.0.0.0:* LISTEN 30735/etcd tcp 0 0 127.0.0.1:2379 0.0.0.0:* LISTEN 30735/etcd tcp 0 0 127.0.0.1:2381 0.0.0.0:* LISTEN 30735/etcd tcp 0 0 127.0.0.1:10257 0.0.0.0:* LISTEN 4185/kube-controlle tcp 0 0 127.0.0.1:10259 0.0.0.0:* LISTEN 4177/kube-scheduler tcp6 0 0 :::10250 :::* LISTEN 30836/kubelet tcp6 0 0 :::6443 :::* LISTEN 30706/kube-apiserve tcp6 0 0 :::10256 :::* LISTEN 30990/kube-proxy |
На рабочих нодах провереям поднятие kubelet и kube-proxy
|
1 |
# netstat -nlptu | grep -E '1025[06]' |
|
1 2 |
tcp6 0 0 :::10256 :::* LISTEN 2061/kube-proxy tcp6 0 0 :::10250 :::* LISTEN 993/kubelet |
Также требуется вручную настроить конфигурационный файл crictl.yaml для работы с подами/контейнерами/образами (взаимодействия с сri containerd)
|
1 2 3 4 5 |
cat <<EOF > /etc/crictl.yaml runtime-endpoint: unix:///run/containerd/containerd.sock image-endpoint: unix:///run/containerd/containerd.sock timeout: 10 EOF |
Проверяем доступ к подам,контейнерам,образам при использовании crictl
|
1 |
# crictl pods |
|
1 |
# crictl ps |
|
1 |
# crictl images |
Установка и настройка Ingress-nginx в качестве Ingress-контроллера
Добавить метку на role1=ingress на перые две worker-ноды k8s-кластера
|
1 |
# for i in {1..2}; do kubectl label nodes node0$ role1=ingress; done |
Проверить наличие установленных меток на нодах
|
1 |
# kubectl get node --show-labels | grep ingress |
Деплой Ingress-controller
|
1 |
# vagrant ssh master01 |
|
1 |
# wget -O /home/vagrant/nginx-ingress.yml https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.47.0/deploy/static/provider/baremetal/deploy.yaml |
|
1 |
# cp nginx-ingress.yml nginx-ingress-original.yml |
Настройки, которые изменены пос равнению с дефолтными настройками
|
1 |
# nano nginx-ingress.yml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
# Source: ingress-nginx/templates/controller-configmap.yaml apiVersion: v1 kind: ConfigMap metadata: ... name: ingress-nginx-controller namespace: ingress-nginx data: proxy-body-size: 128m proxy-buffer-size: 256k server-tokens: "false" server-snippet: | set_real_ip_from 192.168.66.0/24; real_ip_header X-Forwarded-For; real_ip_recursive on; --- .... # Source: ingress-nginx/templates/controller-service.yaml #apiVersion: v1 #kind: Service #metadata: # annotations: # labels: # helm.sh/chart: ingress-nginx-3.33.0 # app.kubernetes.io/name: ingress-nginx # app.kubernetes.io/instance: ingress-nginx # app.kubernetes.io/version: 0.47.0 # app.kubernetes.io/managed-by: Helm # app.kubernetes.io/component: controller # name: ingress-nginx-controller # namespace: ingress-nginx #spec: # type: NodePort # ports: # - name: http # port: 80 # protocol: TCP # targetPort: http # - name: https # port: 443 # protocol: TCP # targetPort: https # selector: # app.kubernetes.io/name: ingress-nginx # app.kubernetes.io/instance: ingress-nginx # app.kubernetes.io/component: controller kind: Deployment metadata: labels: ... name: ingress-nginx-controller namespace: ingress-nginx spec: replicas: 2 strategy: #type: Recreate type: RollingUpdate rollingUpdate: maxSurge: 0 maxUnavailable: 1 .... template: .... spec: #dnsPolicy: ClusterFirst hostNetwork: true dnsPolicy: ClusterFirstWithHostNet affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app.kubernetes.io/name operator: In values: - ingress-nginx topologyKey: "kubernetes.io/hostname" containers: - name: controller .... nodeSelector: role1: ingress serviceAccountName: ingress-nginx .... |
Раздеплоим Ingress-nginx
|
1 |
# kubectl apply -f nginx-ingress.yml |
Проверяем состояние подов в namspace ingress-nginx
|
1 |
# kubectl get pod -n ingress-nginx -w |
Источник:
https://github.com/rotoro-cloud/hardway-cluster/blob/main/Vagrantfile
https://kubernetes.io/docs/setup/production-environment/container-runtimes
https://v1-21.docs.kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm
https://v1-21.docs.kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability
 Опубликовано в рубрике
Опубликовано в рубрике  Метки:
Метки: