 Февраль 23rd, 2019
Февраль 23rd, 2019  Evgeniy Kamenev
Evgeniy Kamenev За основу был взять стек мониторинга отсюда
https://github.com/stefanprodan/swarmprom
В наличие 3 ноды в Docker Swarm-кластере: одна нода — manager и две ноды — worker
|
1 |
# docker node ls |
|
1 2 3 4 |
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION yxbot7la1mh84zdg6c4ca9mgy * lxc Ready Active Leader 18.06.1-ce x2uq0iyuxob9lu2wa59s0kt9t ubuntu161 Ready Active 18.06.1-ce t64s951d2pm5c8xejfv2uwkmc ubuntu162 Ready Active 18.09.1 |
Например, мониторинг стек будем запускать на мастере(на продакшен для этого нужно выделить отдельную ноду, которую нужно добавить в Swarm-кластер и именно на этой ноде запускать мониторинг)
А также имеется одна отдельная нода в ECS-кластере в AWS, которую также нужно мониторить (как ресурсы самой ноды, так и контейнеры,запущенные на ней)
Базовая архитектрная схема мониторинг стека имеет вид
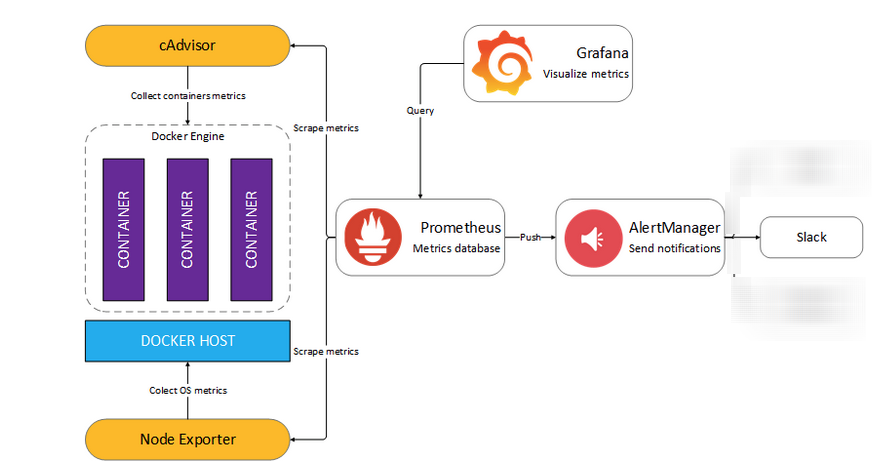
Mониторинг стек состоит из следующих компонентов:
|
1 2 3 4 5 6 7 8 9 10 |
Prometheus – сбор и хранение метрик http://<swarm-ip>:9090 Grafana- визуализация метрик http://<swarm-ip>:3000 AlertManger -отправка сообщений в желаемый канал информации (в нашем случае Slack) http://<swarm-ip>:9093 Unsee – удобный dashboard для Alertmanger http://<swarm-ip>:9094 Caddy – обратный прокис-сервер с обеспечением Basic-аутентификации для Prometheus ,AlertManager, Unsee Node-exporter – сборщик метрик нод/хостов Cadvisor - сборщик метрик контейнеров Blackbox-exorter – мониторинг доступности сайтов MongoDB-exporter – мониторинг mongodb-службы для MongoDB-сервиса, запущенного в Docker Swarm-кластере CouchDB-exporter- мониторинг couchdb-службы для CouchDB-сервиса, запущенного в ECS-кластере |
Все компоненты в Docker-swarm запускаются в контейнерах с помощью docker-compose.yml файла
Иерархия каталогов/файлов имеет следующий вид
|
1 |
# tree |
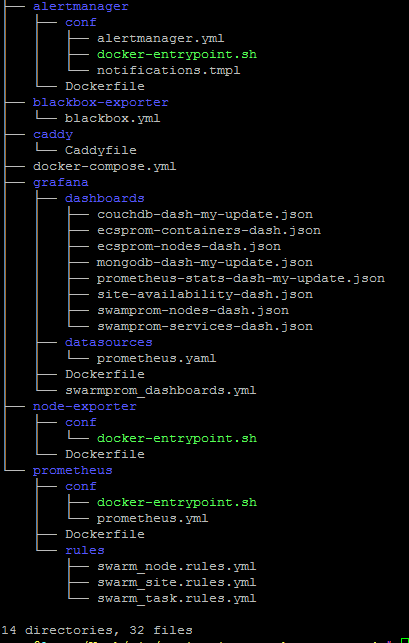
Мониторинг стек запускается командой
|
1 |
# RULES_CONF_VERSION=<version-number> BLACKBOX_CONF_VERSION=<version-number> PROMETHEUS_AWS_ACCESS_KEY='<aws-access-key>' PROMETHEUS_AWS_SECRET_KEY='<aws-secret-key>' SLACK_URL='<slack-url>' SLACK_CHANNEL='<slack-channel>' MONGODB_URI='<mongodb_uri>' ADMIN_PASSWORD=<password> docker stack deploy --with-registry-auth -c docker-compose.yml <my-stack-name> |
Переменные, указанные при запуске/обновлении стека используются ,как переменные окружения в соответствующих контейнерах
в Prometheus — для аутентификации и авторизации в AWS
|
1 2 |
PROMETHEUS_AWS_ACCESS_KEY PROMETHEUS_AWS_SECRET_KEY |
в AlertManager – для отправки уведомлений
|
1 2 |
SLACK_URL SLACK_CHANNEL |
в Mongodb-exporter — для снятия статистики с mongodb в mongodb-сервисе
|
1 |
MONGODB_URI |
в Caddy – пароль для аутентификации в Prometheus, AlertManager, Unsee, а также пароль для аутентификации в Grafana
|
1 |
ADMIN_PASSWORD |
ADMIN_USER(не указывется и по дефолту используется admin)
Prometheus использует правила для мониторинга различных параметров(rules-файлы) в виде docker-конфигов.
Blackbox-exporter также использует docker-config для своего конфигурационного файла.
Поэтому при изменении, например, правил Prometheus, необходимо изменить(увеличить на 1) значение версии файла при запуске/обновлении monitoring-стека(Например, до изменений правил стек запускался с командой RULES_CONF_VERSION=7 …., то после изменений правил стек должен запускаться командой RULES_CONF_VERSION=8)
Аналогично и для blackbox-экспортера (например, запускался до изменений конф.файла blackbox.yml с парметром BLACKBOX_CONF_VERSION=1, а после изменения файла blackbox.yml — должен запускаться с с параметром BLACKBOX_CONF_VERSION=2)
Текущие версии RULES_CONF_VERSION и BLACKBOX_CONF_VERSION доступны через docker service inspect соответствующих сервисов(mon_prometheus или mon_blckbox-exporter).
На ноде в ECS-кластере через ECS tasks/services также запускаются cadvisor, node-exporter, couchdb-exporter
Docker-контейнеры, запускаемые через Docker-compose-файл используют уже существующую overlay сеть, в которой запущены другие сервисы(например, наше приложение)
Т.е. интегрируется в эту сеть не создавая новой сети.
Запуск мониторинг стека в той же сети, что и основные уже запущенные docker-сервисы позволяет prometheus обнаруживать и использовать их как цели для мониторинга используя DNS service discovery по имени сервиса
Когда Prometheus выполняет DNS-запрос, Docker Swarm отдает список IP-адресов каждого контейнера(таска). Используя эти IP-адреса, Prometheus будет обходить SWARM-кий load-balancer(который используется по умолчанию и представляет overlay IP-адрес сервиса т.н. vip-адрес, за которым уже стоят реальные IP-адреса контейнеров, на которых запущен сервис)
и собирать метрики с каждого экспортера инстанса(node-exporter, cadvisor, mongodb-exporter)
Проблема с DNS discovery в Docker Swarm состоит в том, что SWARM не отдает никаких меток/запиcей для контейнеров/тасков, запущенных в Docker SWARM-кластере за исключением overlay IP-адреса, который динамически назначается Docker-ом каждому контейнеру/таску и по которому невозможно определить, какой ноде соответствует экспортер, который имеет такой IP-адрес
Для сопоставления ноды и node-exporter-а, который запускается на этой ноде, в скрипте, который выполняется при запуске контейнера c node-exporter (docker-entrypoint.sh) выполняется создание файла /etc/node-exporter/node-meta.prom в контейнере с node-exporter, в котором указан идентификатор ноды в SWARM-кластере (NODE_ID), а также имя ноды, на которой этот node-exporter запущен(берется из файла /etc/hostname с ноды).
Более подробно об этом у источника
https://github.com/stefanprodan/swarmprom
Prometheus обнаруживает цели для мониторинга:
— в Docker Swarm-кластере — с помощью DNS service discovery(prometheus запускается в той же overlay-сети, как и остальные ноды Docker Swarm кластера)( о чем было рассказано выше)
— в ECS-кластерах с помощью EC2 service discovery
Для обнаружения целей для мониторинга с помощью EC2 service discovery необходимо создать пользователя с соответствующими правами(достаточно привязать политику AmazonEC2ReadOnlyAccess к пользователю) и создать для этого пользователя AWS_ACCESS_KEY и AWS_SECRET_KEY ключи, которые будут использоваться для аутентификации и авторизации в EC2 и использоваться в конфигурационном файле Prometheus
Создание пользователя для аутентификации и авторизации в AWS изложено/доступно в конце статьи
Prometheus хранит данные за месяц, после чего автоматически удаляет/очищает устаревшие данные(—storage.tsdb.retention=750h)
Node-exporter, cadvisor запускаются в GLOBAL-режиме в Docker Swarm-кластере и в DAEMON-режиме в ECS-кластере
Следующие сервисы запускаются только на Monitoring-ноде(это достигается за счет использования .placement.constraints в docker-compose.yml файле,что позволяет запускать определенные сервисы на ноде с определенной меткой)
|
1 2 3 4 5 6 7 |
Prometheus Grafana AlertManger Unsee Caddy Blackbox-exorter MongoDB-exporter |
Установим необходимую метку с ее значением(type=monitoring) для ноды, на которой будем запускать мониторинг стек
|
1 |
# docker node update --label-add type=monitoring lxc |
Проверяем наличие установленной метки
|
1 |
# docker node inspect --pretty lxc |
|
1 2 3 4 5 |
ID: yxbot7la1mh84zdg6c4ca9mgy Labels: - type=monitoring Hostname: lxc …… |
Couchdb-exporter запускается на той же EC2-ноде в ECS-кластере, что и couchdb-сервис(с которого couchdb-eхporter будет собирать метрики)
Запуск Couchdb-exporter с безопасным хранением credentials для доступа и снятия статистики с couchdb-сервиса(couchdn-логин,couchdb-пароль,couchdb-url) в AWS Parameter Store изложены в этой статье
https://kamaok.org.ua/?p=3061
Docker-compose-файл имеет вид
|
1 |
# cat docker-compose.yml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 |
version: "3.6" networks: default: external: true name: prod_default #networks: # net: # driver: overlay # attachable: true volumes: prometheus: {} grafana: {} alertmanager: {} configs: caddy_config: file: ./caddy/Caddyfile blackbox_config: file: ./blackbox-exporter/blackbox.yml name: blackbox.yml-v${BLACKBOX_CONF_VERSION} node_rules: file: ./prometheus/rules/swarm_node.rules.yml name: swarm_node.rules-v${RULES_CONF_VERSION} task_rules: file: ./prometheus/rules/swarm_task.rules.yml name: swarm_task.rules-v${RULES_CONF_VERSION} site_rules: file: ./prometheus/rules/swarm_site.rules.yml name: swarm_site.rules-v${RULES_CONF_VERSION} services: cadvisor: image: google/cadvisor networks: default: {} # - net command: -logtostderr -docker_only volumes: - /var/run/docker.sock:/var/run/docker.sock:ro - /:/rootfs:ro - /var/run:/var/run - /sys:/sys:ro - /var/lib/docker/:/var/lib/docker:ro deploy: mode: global resources: limits: memory: 128M reservations: memory: 64M logging: driver: "json-file" options: max-size: "5m" grafana: image: docker.mydomain.com/grafana:5.4.2 networks: default: {} # - net environment: - GF_SECURITY_ADMIN_USER=${ADMIN_USER:-admin} - GF_SECURITY_ADMIN_PASSWORD=${ADMIN_PASSWORD:-admin} - GF_USERS_ALLOW_SIGN_UP=false #- GF_SERVER_ROOT_URL=${GF_SERVER_ROOT_URL:-localhost} #- GF_SMTP_ENABLED=${GF_SMTP_ENABLED:-false} #- GF_SMTP_FROM_ADDRESS=${GF_SMTP_FROM_ADDRESS:-grafana@test.com} #- GF_SMTP_FROM_NAME=${GF_SMTP_FROM_NAME:-Grafana} #- GF_SMTP_HOST=${GF_SMTP_HOST:-smtp:25} #- GF_SMTP_USER=${GF_SMTP_USER} #- GF_SMTP_PASSWORD=${GF_SMTP_PASSWORD} volumes: - grafana:/var/lib/grafana deploy: mode: replicated replicas: 1 placement: constraints: - node.labels.type == monitoring resources: limits: memory: 128M reservations: memory: 64M logging: driver: "json-file" options: max-size: "5m" alertmanager: image: docker.mydomain.com/alertmanager:v0.15.3 networks: default: {} # - net environment: - SLACK_URL=${SLACK_URL} - SLACK_CHANNEL=${SLACK_CHANNEL} - SLACK_USER=${SLACK_USER:-alertmanager} command: - '--config.file=/etc/alertmanager/alertmanager.yml' - '--storage.path=/alertmanager' volumes: - alertmanager:/alertmanager deploy: mode: replicated replicas: 1 placement: constraints: - node.labels.type == monitoring resources: limits: memory: 128M reservations: memory: 64M logging: driver: "json-file" options: max-size: "5m" unsee: image: cloudflare/unsee:v0.8.0 networks: default: {} # - net environment: - "ALERTMANAGER_URIS=default:http://alertmanager:9093" deploy: mode: replicated replicas: 1 placement: constraints: - node.labels.type == monitoring resources: limits: memory: 128M reservations: memory: 64M logging: driver: "json-file" options: max-size: "5m" node-exporter: image: docker.mydomain.com/node-exporter:v0.17.0 networks: default: {} # - net environment: - NODE_ID={{.Node.ID}} volumes: - /proc:/host/proc:ro - /sys:/host/sys:ro - /:/rootfs:ro - /etc/hostname:/etc/nodename command: - '--path.sysfs=/host/sys' - '--path.procfs=/host/proc' - '--collector.textfile.directory=/etc/node-exporter/' - '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc)($$|/)' - '--no-collector.ipvs' deploy: mode: global resources: limits: memory: 128M reservations: memory: 64M logging: driver: "json-file" options: max-size: "5m" prometheus: image: docker.mydomain.com/prometheus:v2.6.0 networks: default: {} # - net environment: - PROMETHEUS_AWS_ACCESS_KEY=${PROMETHEUS_AWS_ACCESS_KEY} - PROMETHEUS_AWS_SECRET_KEY=${PROMETHEUS_AWS_SECRET_KEY} command: - '--config.file=/etc/prometheus/prometheus.yml' - '--storage.tsdb.path=/prometheus' - '--storage.tsdb.retention=750h' - '--web.enable-lifecycle' volumes: - prometheus:/prometheus configs: - source: node_rules target: /etc/prometheus/swarm_node.rules.yml - source: task_rules target: /etc/prometheus/swarm_task.rules.yml - source: site_rules target: /etc/prometheus/swarm_site.rules.yml deploy: mode: replicated replicas: 1 placement: constraints: - node.labels.type == monitoring resources: limits: memory: 1024M reservations: memory: 512M logging: driver: "json-file" options: max-size: "5m" caddy: image: docker.mydomain.com/caddy ports: - "3000:3000" - "9090:9090" - "9093:9093" - "9094:9094" networks: default: {} # - net environment: - ADMIN_USER=${ADMIN_USER:-admin} - ADMIN_PASSWORD=${ADMIN_PASSWORD:-admin} configs: - source: caddy_config target: /etc/caddy/Caddyfile deploy: mode: replicated replicas: 1 placement: constraints: - node.labels.type == monitoring resources: limits: memory: 128M reservations: memory: 64M logging: driver: "json-file" options: max-size: "5m" blackbox-exporter: image: prom/blackbox-exporter networks: default: {} # - net configs: - source: blackbox_config target: /config/blackbox.yml command: - '--config.file=/config/blackbox.yml' deploy: mode: replicated replicas: 1 placement: constraints: - node.labels.type == monitoring resources: limits: memory: 128M reservations: memory: 64M logging: driver: "json-file" options: max-size: "5m" mongodb-exporter: image: docker.mydomain.com/mongodb-exporter:1.0.0 networks: default: {} # - net environment: - MONGODB_URI=${MONGODB_URI} command: - '-mongodb.uri=${MONGODB_URI}' deploy: mode: replicated replicas: 1 placement: constraints: - node.labels.type == monitoring resources: limits: memory: 128M reservations: memory: 64M logging: driver: "json-file" options: max-size: "5m" |
Docker-контейнеры, запускаемые через Docker-compose-файл используют уже существующую overlay сеть, в которой запущены другие сервисы
Если необходимо запускать monitoring стек в своей отдельной сети, тогда закомментируем то, что сейчас используется и расскомментируем то, что сейчас закомментировано
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
networks: default: external: true name: prod_default #networks: # net: # driver: overlay # attachable: true И во всех сервисах networks: default: {} # - net |
Создаем необходимые тома для постоянного хранения своих данных Prometheus-ом, grafana-ой, alertmanager-ом
|
1 2 3 4 |
volumes: prometheus: {} grafana: {} alertmanager: {} |
Создание Docker-конфигов,которые используются для конфигурационных файлов
Caddy – Caddyfile
Blackbox-exporter – blackbox.yml
Prometheus – node_rules, task_rules ,site_rules – файлы описания правил для срабатывания оповещения
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
configs: caddy_config: file: ./caddy/Caddyfile blackbox_config: file: ./blackbox-exporter/blackbox.yml name: blackbox.yml-v${BLACKBOX_CONF_VERSION} node_rules: file: ./prometheus/rules/swarm_node.rules.yml name: swarm_node.rules-v${RULES_CONF_VERSION} task_rules: file: ./prometheus/rules/swarm_task.rules.yml name: swarm_task.rules-v${RULES_CONF_VERSION} site_rules: file: ./prometheus/rules/swarm_site.rules.yml name: swarm_site.rules-v${RULES_CONF_VERSION} |
Cadvisor, Unsee, Blackbox-exporter используем официальные публично доступные
|
1 2 3 |
google/cadvisor cloudflare/unsee:v0.8.0 prom/blackbox-exporter |
Prometheus, Alertmanager, Node-exporter, Grafana — собираем свои образы на основе Dockerfile
|
1 |
# cd monitoring-stack |
Перед сборкой образов, проверить/убедиться, что все sh-файлы имеют бит исполнения
Prometheus
|
1 |
(cd prometheus/; docker build -t docker.mydomain.com/prometheus:v2.6.0 . && docker push docker.mydomain.com/prometheus:v2.6.0) |
Alertmanager
|
1 |
(cd alertmanager/; docker build -t docker.mydomain.com/alertmanager:v0.15.3 . && docker push docker.mydomain.com/alertmanager:v0.15.3) |
Node-exporter
|
1 |
(cd node-exporter/; docker build -t docker.mydomain.com/node-exporter:v0.17.0 . && docker push docker.mydomain.com/node-exporter:v0.17.0) |
Grafana
|
1 |
(cd grafana/; docker build -t docker.mydomain.com/grafana:5.4.2 . && docker push docker.mydomain.com/grafana:5.4.2) |
Сaddy — просто перетегируем образ с stefanprodan/caddy
|
1 |
# docker pull stefanprodan/caddy |
|
1 |
# docker tag stefanprodan/caddy docker.mydomain.com/caddy |
|
1 |
# docker push docker.mydomain.com/caddy |
Mongodb-exporter – собираем Docker-образ на основе офицального Docker-файла
|
1 |
# git clone git@github.com:dcu/mongodb_exporter.git && cd mongodb_exporter/ |
|
1 |
# docker build -t docker.mydomain.com/mongodb-exporter:1.0.0 . |
|
1 |
# docker push docker.mydomain.com/mongodb-exporter:1.0.0 |
Для проверки синтаксиса конфигурационного файла Prometheus(prometheus.yml) и файлов с правилами(swarm_node.rules.yml, swarm_task.rules.yml, swarm_site.rules.yml) удобно/можно использовать утилиту promtool, которая доступна в архиве с prometheus
Находясь в каталоге с мониторинг стеком(monitoring-stack-swarm-prod)
|
1 |
# cd monitoring-stack-swarm-prod |
Переходим на пару каталогов выше, загружаем и распаковываем архив с prometheus
|
1 |
# cd ../../ |
|
1 |
# wget https://github.com/prometheus/prometheus/releases/download/v2.6.0/prometheus-2.6.0.linux-amd64.tar.gz |
|
1 |
# tar xvzf prometheus-2.6.0.linux-amd64.tar.gz && rm prometheus-2.6.0.linux-amd64.tar.gz |
После распаковки архива доступна утилита promtool
|
1 |
# cd monitoring-stack-swarm-prod |
Команды для проверки файла с правилами prometheus
|
1 |
# ../../prometheus-2.6.0.linux-amd64/promtool check rules prometheus/rules/swarm_node.rules.yml |
|
1 |
# ../../prometheus-2.6.0.linux-amd64/promtool check rules prometheus/rules/swarm_task.rules.yml |
|
1 |
# ../../prometheus-2.6.0.linux-amd64/promtool check rules prometheus/rules/swarm_site.rules.yml |
Или проверка конфигурационного файла prometheus и всех правил с помощью одной команды
|
1 |
# (cd prometheus/conf/ && ln -s ../rules/swarm_* .) && ../../prometheus-2.6.0.linux-amd64/promtool check config prometheus/conf/prometheus.yml && echo $? && rm prometheus/conf/swarm_*.yml |
|
1 2 3 4 5 6 7 8 9 10 11 |
Checking prometheus/conf/prometheus.yml SUCCESS: 3 rule files found Checking prometheus/conf/swarm_node.rules.yml SUCCESS: 8 rules found Checking prometheus/conf/swarm_task.rules.yml SUCCESS: 18 rules found Checking prometheus/conf/swarm_site.rules.yml SUCCESS: 1 rules found |
Содержимое файлов стека
AlertManager
Изменяем дефолтные настройки параметров title и text путем созадния собственных шаблонов, которые используются в этих параметрах
AlertManager отправляет сообщения в соответствующий канал информирования (в нашем случае в Slack)
|
1 |
# cat alertmanager/conf/alertmanager.yml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
route: receiver: 'slack' receivers: - name: 'slack' slack_configs: - send_resolved: true title: '{{ template "custom_title" . }}' text: '{{ template "custom_slack_message" . }}' #username: <user># #channel: <channel># #api_url: <url># templates: - /etc/alertmanager/notifications.tmpl |
Файл с описанием шаблонов
|
1 |
# cat alertmanager/conf/notifications.tmpl |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{{ define "__single_message_title" }}{{ range .Alerts.Firing }}{{ .Labels.alertname }} @ {{ .Annotations.summary }}{{ end }}{{ range .Alerts.Resolved }}{{ .Labels.alertname }} @ {{ .Annotations.summary }}{{ end }}{{ end }} {{ define "custom_title" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ if or (and (eq (len .Alerts.Firing) 1) (eq (len .Alerts.Resolved) 0)) (and (eq (len .Alerts.Firing) 0) (eq (len .Alerts.Resolved) 1)) }}{{ template "__single_message_title" . }}{{ end }}{{ end }} {{ define "custom_slack_message" }} {{ if or (and (eq (len .Alerts.Firing) 1) (eq (len .Alerts.Resolved) 0)) (and (eq (len .Alerts.Firing) 0) (eq (len .Alerts.Resolved) 1)) }} {{ range .Alerts.Firing }}{{ .Annotations.description }}{{ end }}{{ range .Alerts.Resolved }}{{ .Annotations.description }}{{ end }} {{ else }} {{ if gt (len .Alerts.Firing) 0 }} *Alerts Firing:* {{ range .Alerts.Firing }}- {{ .Annotations.summary }}: {{ .Annotations.description }} {{ end }}{{ end }} {{ if gt (len .Alerts.Resolved) 0 }} *Alerts Resolved:* {{ range .Alerts.Resolved }}- {{ .Annotations.summary }}: {{ .Annotations.description }} {{ end }}{{ end }} {{ end }} {{ end }} |
Более подробно здесь
https://medium.com/quiq-blog/better-slack-alerts-from-prometheus-49125c8c672b
Динамическая замена параметров SLACK_URL, SLACK_CHANNEL, SLACK_USER на указанные либо при запуске мониторинг стека либо указанных в docker-compose.yml файле
|
1 |
# cat alertmanager/conf/docker-entrypoint.sh |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#!/bin/sh -e cat /etc/alertmanager/alertmanager.yml |\ sed "s@#api_url: <url>#@api_url: '$SLACK_URL'@g" |\ sed "s@#channel: <channel>#@channel: '#$SLACK_CHANNEL'@g" |\ sed "s@#username: <user>#@username: '$SLACK_USER'@g" > /tmp/alertmanager.yml mv /tmp/alertmanager.yml /etc/alertmanager/alertmanager.yml set -- /bin/alertmanager "$@" exec "$@" |
Dockerfile для сборки образа AlertManager
|
1 |
# cat alertmanager/Dockerfile |
|
1 2 3 4 5 6 7 |
FROM prom/alertmanager:v0.15.3 COPY conf /etc/alertmanager/ ENTRYPOINT [ "/etc/alertmanager/docker-entrypoint.sh" ] CMD [ "--config.file=/etc/alertmanager/alertmanager.yml", \ "--storage.path=/alertmanager" ] |
Blackbox-exporter
Конфигурационный файл
|
1 |
# cat blackbox-exporter/blackbox.yml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
modules: http_2xx-general: prober: http timeout: 10s http: valid_status_codes: [200,302,301,304] # Defaults to 2xx method: GET no_follow_redirects: false fail_if_ssl: false fail_if_not_ssl: false preferred_ip_protocol: "ip4" # defaults to "ip6" tls_config: insecure_skip_verify: true http_2xx-kamaok: prober: http timeout: 10s http: valid_status_codes: [200,302,301,304] # Defaults to 2xx method: GET no_follow_redirects: false fail_if_ssl: false fail_if_not_ssl: false fail_if_not_matches_regexp: - "My certifications" preferred_ip_protocol: "ip4" # defaults to "ip6" tls_config: insecure_skip_verify: true http_2xx-nexus: prober: http timeout: 10s http: valid_status_codes: [200,302,301,304] # Defaults to 2xx method: GET no_follow_redirects: false fail_if_ssl: false fail_if_not_ssl: false fail_if_not_matches_regexp: - "Nexus Repository Manager" preferred_ip_protocol: "ip4" # defaults to "ip6" tls_config: insecure_skip_verify: true http_2xx-sonarqube: prober: http timeout: 10s http: valid_status_codes: [200,302,301,304] # Defaults to 2xx method: GET no_follow_redirects: false fail_if_ssl: false fail_if_not_ssl: false fail_if_not_matches_regexp: - "SonarQube" preferred_ip_protocol: "ip4" # defaults to "ip6" tls_config: insecure_skip_verify: true http_post_2xx: prober: http timeout: 10s http: method: POST tcp_connect: prober: tcp timeout: 10s ssh_banner: prober: tcp timeout: 10s tcp: query_response: - expect: "^SSH-2.0-" icmp-general: prober: icmp timeout: 5s icmp: preferred_ip_protocol: "ip4" # source_ip_address: "127.0.0.1" |
В модулях
|
1 2 3 |
http_2xx-kamaok http_2xx-nexus http_2xx-sonarqube |
Определяем допустимые/желаемые коды ответов(200,302,301,304)
Regexps/patterns, которые должны быть найдены на стартовых страницах сайтов, которые мониторятся blackbox-экспортером
Эти модули будут использоваться/подключаться в конфигурационном файле Prometheus
Caddy
Конфигурационный файл имеет вид
|
1 |
# cat caddy/Caddyfile |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
:9090 { basicauth / {$ADMIN_USER} {$ADMIN_PASSWORD} proxy / prometheus:9090 { transparent } errors stderr tls off } :9093 { basicauth / {$ADMIN_USER} {$ADMIN_PASSWORD} proxy / alertmanager:9093 { transparent } errors stderr tls off } :9094 { basicauth / {$ADMIN_USER} {$ADMIN_PASSWORD} proxy / unsee:8080 { transparent } errors stderr tls off } :3000 { proxy / grafana:3000 { transparent websocket } errors stderr tls off } |
По умолчанию значения переменных ADMIN_USER и ADMIN_PASSWORD берутся из файла prometheus.conf(задаются при описании caddy-сервиса)
|
1 2 3 4 5 |
… environment: - ADMIN_USER=${ADMIN_USER:-admin} - ADMIN_PASSWORD=${ADMIN_PASSWORD:-admin} … |
Но при запуске мониторинг стека мы переопределяем значение переменной ADMIN_PASSWORD с помощью переменной окружения
Grafana
Docker-файл имеет вид
|
1 |
# cat grafana/Dockerfile |
|
1 2 3 4 5 6 7 8 9 10 |
FROM grafana/grafana:5.4.2 # https://hub.docker.com/r/grafana/grafana/tags/ COPY datasources /etc/grafana/provisioning/datasources/ COPY swarmprom_dashboards.yml /etc/grafana/provisioning/dashboards/ COPY dashboards /etc/grafana/dashboards/ ENV GF_SECURITY_ADMIN_PASSWORD=admin \ GF_SECURITY_ADMIN_USER=admin \ GF_PATHS_PROVISIONING=/etc/grafana/provisioning/ |
Grafana поддержует динамический provisioning как источников данных/метрик(datasource), так и dashboard-ов
http://docs.grafana.org/administration/provisioning/
Файл для динамического provisioning datasource с нашего prometheus-сервера
|
1 |
# cat grafana/datasources/prometheus.yaml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: 1 deleteDatasources: - name: Prometheus datasources: - name: Prometheus type: prometheus access: proxy url: http://prometheus:9090 isDefault: true version: 1 editable: true |
Файл для подключения динамического provisioning dashboard-ов
|
1 |
# cat grafana/swarmprom_dashboards.yml |
|
1 2 3 4 5 6 7 8 9 10 11 |
apiVersion: 1 providers: - name: 'default' orgId: 1 folder: '' type: file disableDeletion: false editable: true options: path: /etc/grafana/dashboards |
В grafana/dashboards размещаем dashboard-ы
Например, у меня их несколько — для нод в Swarm и ECS-кластерах, для контейнеров в
Swarm и ECS-кластерах, для сайтов, для mongodb,couchdb,prometheus-сервисов
|
1 |
# ls -l grafana/dashboards/ |
|
1 2 3 4 5 6 7 8 9 |
total 304 -rw-r--r-- 1 root root 27955 Jan 31 10:48 couchdb-dash-my-update.json -rw-r--r-- 1 root root 45335 Feb 1 11:27 ecsprom-containers-dash.json -rw-r--r-- 1 root root 44979 Feb 1 11:26 ecsprom-nodes-dash.json -rw-r--r-- 1 root root 26185 Jan 31 10:48 mongodb-dash-my-update.json -rw-r--r-- 1 root root 29035 Jan 31 10:48 prometheus-stats-dash-my-update.json -rw-r--r-- 1 root root 24326 Jan 31 10:48 site-availability-dash.json -rw-r--r-- 1 root root 49650 Jan 31 10:48 swamprom-nodes-dash.json -rw-r--r-- 1 root root 47147 Jan 31 10:48 swamprom-services-dash.json |
Node-exporter
Dockerfile имееет вид
|
1 |
# cat node-exporter/Dockerfile |
|
1 2 3 4 5 6 7 8 9 10 |
FROM prom/node-exporter:v0.17.0 ENV NODE_ID=none USER root COPY conf /etc/node-exporter/ ENTRYPOINT [ "/etc/node-exporter/docker-entrypoint.sh" ] CMD [ "/bin/node_exporter" ] |
Стартовый скрипт(docker-entrypoint.sh) создает файл в node-exporter контейнере с необходимым содержимым для определения ноды, на которой запущен этот node-exporter
После чего непосредственно запускается node-exporter
|
1 |
# cat node-exporter/conf/docker-entrypoint.sh |
|
1 2 3 4 5 6 7 8 |
#!/bin/sh -e NODE_NAME=$(cat /etc/nodename) echo "node_meta{node_id=\"$NODE_ID\", container_label_com_docker_swarm_node_id=\"$NODE_ID\", node_name=\"$NODE_NAME\"} 1" > /etc/node-exporter/node-meta.prom set -- /bin/node_exporter "$@" exec "$@" |
Prometheus
Конфигурационный файл имеет вид
|
1 |
# cat prometheus/Dockerfile |
|
1 2 3 4 5 6 7 8 9 |
FROM prom/prometheus:v2.6.0 # https://hub.docker.com/r/prom/prometheus/tags/ COPY conf /etc/prometheus/ ENTRYPOINT [ "/etc/prometheus/docker-entrypoint.sh" ] CMD [ "--config.file=/etc/prometheus/prometheus.yml", \ "--storage.tsdb.path=/prometheus" ] |
Стартовый скрипт(docker-entrypoint.sh), который выполняется в качестве ENTRYPOINT имеет вид
|
1 |
# cat prometheus/conf/docker-entrypoint.sh |
|
1 2 3 4 5 6 7 8 9 10 11 |
#!/bin/sh –e cat /etc/prometheus/prometheus.yml |\ sed "s@#access_key: <access_key>#@access_key: '${PROMETHEUS_AWS_ACCESS_KEY}'@g" |\ sed "s@#secret_key: <secret_key>#@secret_key: '${PROMETHEUS_AWS_SECRET_KEY}'@g" > /tmp/prometheus.yml mv /tmp/prometheus.yml /etc/prometheus/prometheus.yml set -- /bin/prometheus "$@" exec "$@" |
В нем выполняется динамическая замена access_key и secret_key ключей, которые передаются, как переменные окружения PROMETHEUS_AWS_ACCESS_KEY и PROMETHEUS_AWS_SECRET_KEY при запуске мониторинг стека
Также происходит непосредственно запуск Prometheus через его бинарный файл, а в качестве аргументов передаются параметры из поля CMD, указанного в Dockerfile.
Правила мониторинга, на основании которых запускается процесс оповещения имеют вид
Правила для мониторинга нод
|
1 |
# cat prometheus/rules/swarm_node.rules.yml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 |
groups: - name: nodes rules: - alert: node_cpu_usage_70 expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[1m]) * ON(instance) GROUP_LEFT(node_name) node_meta * 100) BY (node_name)) > 70 for: 1m labels: severity: warning annotations: description: Swarm node {{ $labels.node_name }} CPU usage is at {{ humanize $value}}%. summary: CPU alert for Swarm node '{{ $labels.node_name }}' # - alert: node_cpu_usage_90 expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[1m]) * ON(instance) GROUP_LEFT(node_name) node_meta * 100) BY (node_name)) > 90 for: 1m labels: severity: critical annotations: description: Swarm node {{ $labels.node_name }} CPU usage is at {{ humanize $value}}%. summary: CPU alert for Swarm node '{{ $labels.node_name }}' # - alert: node_memory_usage_90 expr: sum(((node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes) * ON(instance) GROUP_LEFT(node_name) node_meta * 100) BY (node_name) > 90 for: 5m labels: severity: warning annotations: description: Swarm node {{ $labels.node_name }} memory usage is at {{ humanize $value}}%. summary: Memory alert for Swarm node '{{ $labels.node_name }}' # - alert: node_memory_usage_95 expr: sum(((node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes) * ON(instance) GROUP_LEFT(node_name) node_meta * 100) BY (node_name) > 95 for: 5m labels: severity: critical annotations: description: Swarm node {{ $labels.node_name }} memory usage is at {{ humanize $value}}%. summary: Memory alert for Swarm node '{{ $labels.node_name }}' # - alert: node_disk_usage_80 expr: ((node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"}) * 100 / node_filesystem_size_bytes{mountpoint="/"}) * ON(instance) GROUP_LEFT(node_name) node_meta > 80 for: 1m labels: severity: warning annotations: description: Swarm node {{ $labels.node_name }} disk usage is at {{ humanize $value}}%. summary: Disk alert for Swarm node '{{ $labels.node_name }}' # - alert: node_disk_usage_90 expr: ((node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"}) * 100 / node_filesystem_size_bytes{mountpoint="/"}) * ON(instance) GROUP_LEFT(node_name) node_meta > 90 for: 1m labels: severity: critical annotations: description: Swarm node {{ $labels.node_name }} disk usage is at {{ humanize $value}}%. summary: Disk alert for Swarm node '{{ $labels.node_name }}' # - alert: node_disk_fill_rate_6h expr: predict_linear(node_filesystem_free_bytes{mountpoint="/"}[1h], 6 * 3600) * ON(instance) GROUP_LEFT(node_name) node_meta < 0 for: 1h labels: severity: critical annotations: description: Swarm node {{ $labels.node_name }} disk is going to fill up in 6h. summary: Disk fill alert for Swarm node '{{ $labels.node_name }}' # - alert: instance_down expr: up == 0 for: 2m labels: severity: critical annotations: description: "Instance {{ $labels.instance }} of job {{ $labels.job }} has been down for more than 2 minutes." summary: "Instance {{ $labels.instance }} down" |
Правила для мониторинга контейнеров
|
1 |
# cat prometheus/rules/swarm_task.rules.yml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 |
groups: - name: tasks rules: - alert: task_high_cpu_usage_SWARM_cluster_80 expr: sum(rate(container_cpu_usage_seconds_total{container_label_com_docker_swarm_task_name=~".+"}[1m])) BY (container_label_com_docker_swarm_task_name, container_label_com_docker_swarm_node_id) * 100 > 80 for: 1m labels: severity: critical annotations: description: '{{ $labels.container_label_com_docker_swarm_task_name }} on ''{{ $labels.container_label_com_docker_swarm_node_id }}'' CPU usage is at {{ humanize $value}}%.' summary: CPU alert for Swarm task '{{ $labels.container_label_com_docker_swarm_task_name }}' on '{{ $labels.container_label_com_docker_swarm_node_id }}' # - alert: task_high_memory_usage_SWARM_cluster_200MB expr: sum(container_memory_rss{container_label_com_docker_swarm_task_name!~".+prometheus.+",container_label_com_docker_swarm_task_name!~".+jenkins.+",container_label_com_docker_swarm_task_name=~".+"}) by(container_label_com_docker_swarm_task_name, container_label_com_docker_swarm_node_id) > 2e+08 for: 5m labels: severity: warning annotations: description: '{{ $labels.container_label_com_docker_swarm_task_name }} on ''{{ $labels.container_label_com_docker_swarm_node_id }}'' memory usage is {{ humanize $value}}.' summary: Memory alert for Swarm task '{{ $labels.container_label_com_docker_swarm_task_name }}' on '{{ $labels.container_label_com_docker_swarm_node_id }}' # - alert: task_high_memory_usage_SWARM_cluster_400MB expr: sum(container_memory_rss{container_label_com_docker_swarm_task_name!~".+prometheus.+",container_label_com_docker_swarm_task_name!~".+jenkins.+",container_label_com_docker_swarm_task_name=~".+"}) BY (container_label_com_docker_swarm_task_name, container_label_com_docker_swarm_node_id) > 4e+08 for: 5m labels: severity: critical annotations: description: '{{ $labels.container_label_com_docker_swarm_task_name }} on ''{{ $labels.container_label_com_docker_swarm_node_id }}'' memory usage is {{ humanize $value}}.' summary: Memory alert for Swarm task '{{ $labels.container_label_com_docker_swarm_task_name }}' on '{{ $labels.container_label_com_docker_swarm_node_id }}' # - alert: task_high_memory_usage_SWARM_cluster_prometheus_800MB expr: sum(container_memory_rss{container_label_com_docker_swarm_task_name=~".+prometheus.+"}) by(container_label_com_docker_swarm_task_name, container_label_com_docker_swarm_node_id) > 8e+08 for: 5m labels: severity: critical annotations: description: '{{ $labels.container_label_com_docker_swarm_task_name }} on ''{{ $labels.container_label_com_docker_swarm_node_id }}'' memory usage is {{ humanize $value}}.' summary: Memory alert for Swarm task '{{ $labels.container_label_com_docker_swarm_task_name }}' on '{{ $labels.container_label_com_docker_swarm_node_id }}' - alert: task_high_memory_usage_SWARM_cluster_jenkins_850MB expr: sum(container_memory_rss{container_label_com_docker_swarm_task_name=~".+jenkins.+"}) by(container_label_com_docker_swarm_task_name, container_label_com_docker_swarm_node_id) > 8.5e+08 for: 5m labels: severity: critical annotations: description: '{{ $labels.container_label_com_docker_swarm_task_name }} on ''{{ $labels.container_label_com_docker_swarm_node_id }}'' memory usage is {{ humanize $value}}.' summary: Memory alert for Swarm task '{{ $labels.container_label_com_docker_swarm_task_name }}' on '{{ $labels.container_label_com_docker_swarm_node_id }}' # - alert: task_high_cpu_usage_ECS_cluster_80 expr: sum by (container_label_com_amazonaws_ecs_container_name,node_id) (rate(container_cpu_usage_seconds_total{container_label_com_amazonaws_ecs_cluster=~".+",container_label_com_amazonaws_ecs_container_name=~".+",node_id=~".+"}[5m])) * 100 > 80 for: 5m labels: severity: critical annotations: description: '{{ $labels.container_label_com_amazonaws_ecs_container_name }} on ''{{ $labels.node_id }}'' Cpu usage is at {{ humanize $value}}.' summary: CPU alert for ECS-task '{{ $labels.container_label_com_amazonaws_ecs_container_name }}' on '{{ $labels.node_id }}' # - alert: task_high_memory_usage_ECS_cluster_200MB expr: sum(avg_over_time(container_memory_usage_bytes{container_label_com_amazonaws_ecs_cluster=~".+",container_label_com_amazonaws_ecs_container_name!~"myservicename",container_label_com_amazonaws_ecs_container_name!~"db",container_label_com_amazonaws_ecs_container_name=~".+",node_id=~".+"}[5m])) by (container_label_com_amazonaws_ecs_container_name,node_id) > 2e+08 for: 5m labels: severity: warning annotations: description: '{{ $labels.container_label_com_amazonaws_ecs_container_name }} on ''{{ $labels.node_id }}'' memory usage is {{ humanize $value}}.' summary: Memory alert for ECS-task '{{ $labels.container_label_com_amazonaws_ecs_container_name }}' on '{{ $labels.node_id }}' # - alert: task_high_memory_usage_ECS_cluster_400MB expr: sum(avg_over_time(container_memory_usage_bytes{container_label_com_amazonaws_ecs_cluster=~".+",container_label_com_amazonaws_ecs_container_name!~"myservicename",container_label_com_amazonaws_ecs_container_name!~"db",container_label_com_amazonaws_ecs_container_name=~".+",node_id=~".+"}[5m])) by (container_label_com_amazonaws_ecs_container_name,node_id) > 4e+08 for: 5m labels: severity: critical annotations: description: '{{ $labels.container_label_com_amazonaws_ecs_container_name }} on ''{{ $labels.node_id }}'' memory usage is {{ humanize $value}}.' summary: Memory alert for ECS-task '{{ $labels.container_label_com_amazonaws_ecs_container_name }}' on '{{ $labels.node_id }}' # - alert: task_high_memory_usage_ECS_cluster_myservicename_4.2GB expr: avg_over_time(container_memory_usage_bytes{node_id=~".+",container_label_com_amazonaws_ecs_cluster=~".+",container_label_com_amazonaws_ecs_container_name=~"myservicename"}[5m]) > 4.2e+09 for: 5m labels: severity: critical annotations: description: '{{ $labels.container_label_com_amazonaws_ecs_container_name }} on ''{{ $labels.node_id }}'' memory usage is {{ humanize $value}}.' summary: Memory alert for ECS-task '{{ $labels.container_label_com_amazonaws_ecs_container_name }}' on '{{ $labels.node_id }}' - alert: task_high_memory_usage_ECS_cluster_db_1.2GB expr: avg_over_time(container_memory_usage_bytes{node_id=~".+",container_label_com_amazonaws_ecs_cluster=~".+",container_label_com_amazonaws_ecs_container_name=~"db"}[5m]) > 1.2e+09 for: 5m labels: severity: critical annotations: description: '{{ $labels.container_label_com_amazonaws_ecs_container_name }} on ''{{ $labels.node_id }}'' memory usage is {{ humanize $value}}.' summary: Memory alert for ECS-task '{{ $labels.container_label_com_amazonaws_ecs_container_name }}' on '{{ $labels.node_id }}' - alert: Service unsee is down in SWARM cluster expr: absent(container_memory_usage_bytes{container_label_com_docker_swarm_service_name=~".+_unsee"}) for: 2m labels: severity: critical annotations: description: Service 'unsee' is down for more 2 minutes summary: Service alert for SWARM service 'unsee' - alert: Service mongodb-exporter is down in SWARM cluster expr: absent(container_memory_usage_bytes{container_label_com_docker_swarm_service_name=~".+_mongodb-exporter"}) for: 2m labels: severity: critical annotations: description: Service 'mongodb-exporter' is down for more 2 minutes summary: Service alert for SWARM service 'mongodb-exporter' - alert: Service prometheus is down in SWARM cluster expr: absent(container_memory_usage_bytes{container_label_com_docker_swarm_service_name=~".+_prometheus"}) for: 2m labels: severity: critical annotations: description: Service 'prometheus' is down for more 2 minutes summary: Service alert for SWARM service 'prometheus' - alert: Service grafana is down in SWARM cluster expr: absent(container_memory_usage_bytes{container_label_com_docker_swarm_service_name=~".+_grafana"}) for: 2m labels: severity: critical annotations: description: Service 'grafana' is down for more 2 minutes summary: Service alert for SWARM service 'grafana' - alert: Service alertmanager is down in SWARM cluster expr: absent(container_memory_usage_bytes{container_label_com_docker_swarm_service_name=~".+_alertmanager"}) for: 2m labels: severity: critical annotations: description: Service 'alertmanager' is down for more 2 minutes summary: Service alert for SWARM service 'alertmanager' - alert: Service caddy is down in SWARM cluster expr: absent(container_memory_usage_bytes{container_label_com_docker_swarm_service_name=~".+_caddy"}) for: 2m labels: severity: critical annotations: description: Service 'caddy' is down for more 2 minutes summary: Service alert for SWARM service 'caddy' - alert: Service myservicename is down in ECS cluster expr: absent(container_memory_usage_bytes{container_label_com_amazonaws_ecs_task_definition_family=~"myservicename"}) for: 2m labels: severity: critical annotations: description: Service 'couchdb' is down for more 2 minutes summary: Service alert for ECS service 'myservicename' - alert: Service db is down in ECS cluster expr: absent(container_memory_usage_bytes{container_label_com_amazonaws_ecs_task_definition_family=~"db"}) for: 2m labels: severity: critical annotations: description: Service 'couchdb' is down for more 2 minutes summary: Service alert for ECS service 'db' - alert: Service couchdb is down in ECS cluster expr: absent(container_memory_usage_bytes{container_label_com_amazonaws_ecs_task_definition_family=~"couchdb"}) for: 2m labels: severity: critical annotations: description: Service 'couchdb' is down for more 2 minutes summary: Service alert for ECS service 'couchdb' - alert: Service couchdb-exporter is down in ECS cluster expr: absent(container_memory_usage_bytes{container_label_com_amazonaws_ecs_task_definition_family=~"couchdb-exporter.+"}) for: 2m labels: severity: critical annotations: description: Service 'couchdb-exporter' is down for more 2 minutes summary: Service alert for ECS service 'couchdb-exporter' - alert: task_high_memory_usage_SWARM_cluster_percent_80 expr: ( sum by(container_label_com_docker_swarm_service_name, container_label_com_docker_swarm_node_id) (avg_over_time(container_memory_usage_bytes{container_label_com_docker_swarm_node_id=~".+", id=~"/docker/.+"}[1m])) / (sum by(container_label_com_docker_swarm_service_name, container_label_com_docker_swarm_node_id) (container_spec_memory_limit_bytes{container_label_com_docker_swarm_service_name=~".+_prometheus|.+_grafana|.+_alertmanager|.+_caddy|.+_unsee|.+cadvisor|.+node-exporter|.+_mongodb-exporter|.+blackbox-exporter",container_label_com_docker_swarm_node_id=~".+"}))) * 100 > 80 for: 5m labels: severity: critical annotations: description: '{{ $labels.container_label_com_docker_swarm_service_name }} on ''{{ $labels.container_label_com_docker_swarm_node_id }}'' memory usage is {{ humanize $value}}%.' summary: Memory alert for Swarm task '{{ $labels.container_label_com_docker_swarm_service_name }}' on '{{ $labels.container_label_com_docker_swarm_node_id }}' # - alert: task_high_memory_usage_ECS_cluster_percent_80 expr: (sum by (container_label_com_amazonaws_ecs_task_definition_family,node_id) (container_memory_usage_bytes{container_label_com_amazonaws_ecs_task_definition_family=~".+"}) / sum by(container_label_com_amazonaws_ecs_task_definition_family,node_id) (container_spec_memory_limit_bytes{node_id=~".+",container_label_com_amazonaws_ecs_task_definition_family=~"myservicename|couchdb|db"}) ) * 100 > 80 for: 5m labels: severity: critical annotations: description: '{{ $labels.container_label_com_amazonaws_ecs_task_definition_family }} on ''{{ $labels.node_id }}'' memory usage is {{ humanize $value}}%.' summary: Memory alert for ECS task '{{ $labels.container_label_com_amazonaws_ecs_task_definition_family }}' on '{{ $labels.node_id }}' |
Правила для мониторинга сайтов
|
1 |
# cat prometheus/rules/swarm_site.rules.yml |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
groups: - name: sites rules: - alert: site_down expr: probe_success{instance=~"http.+"} == 0 for: 1m labels: severity: critical annotations: description: Site {{ $labels.instance }} isn't available(down) for more than 1 minutes summary: Site '{{ $labels.instance }}' isn't available for more than 1 minutes |
Конфигурационный файл Prometheus имеет вид
|
1 |
# cat prometheus/conf/prometheus.yml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 |
global: scrape_interval: 15s evaluation_interval: 15s external_labels: monitor: 'prometheus-prod' rule_files: - "swarm_node.rules.yml" - "swarm_task.rules.yml" - "swarm_site.rules.yml" alerting: alert_relabel_configs: - regex: '(container_label_com_amazonaws_ecs_task_arn|container_label_com_amazonaws_ecs_task_definition_version|id|image|container_label_maintainer)' action: labeldrop alertmanagers: - static_configs: - targets: - alertmanager:9093 scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'cadvisor' dns_sd_configs: - names: - 'tasks.cadvisor' type: 'A' port: 8080 - job_name: 'node-exporter' dns_sd_configs: - names: - 'tasks.node-exporter' type: 'A' port: 9100 - job_name: 'mongodb-exporter' dns_sd_configs: - names: - 'tasks.mongodb-exporter' type: 'A' port: 9001 - job_name: 'ecs-node-exporter' ec2_sd_configs: - region: eu-west-1 #access_key: <access_key># #secret_key: <secret_key># refresh_interval: 30s port: 9999 relabel_configs: - source_labels: [__meta_ec2_tag_ecsmonitoring] regex: prometheus-prod.* action: keep - source_labels: [__meta_ec2_public_ip] target_label: __address__ replacement: '${1}:9999' - source_labels: [__meta_ec2_public_dns_name] target_label: instance - source_labels: [__meta_ec2_instance_id] target_label: node_id - job_name: 'ecs-cadvisor' ec2_sd_configs: - region: eu-west-1 #access_key: <access_key># #secret_key: <secret_key># refresh_interval: 30s port: 8888 relabel_configs: - source_labels: [__meta_ec2_tag_ecsmonitoring] regex: prometheus-prod.* action: keep - source_labels: [__meta_ec2_public_ip] target_label: __address__ replacement: '${1}:8888' - source_labels: [__meta_ec2_public_dns_name] target_label: instance - source_labels: [__meta_ec2_instance_id] target_label: node_id - job_name: 'ecs-couchdb-exporter' ec2_sd_configs: - region: eu-west-1 #access_key: <access_key># #secret_key: <secret_key># refresh_interval: 30s port: 9984 relabel_configs: - source_labels: [__meta_ec2_tag_ecsmonitoring] regex: prometheus-prod.* action: keep - source_labels: [__meta_ec2_public_ip] target_label: __address__ replacement: '${1}:9984' - source_labels: [__meta_ec2_public_dns_name] target_label: instance - source_labels: [__meta_ec2_instance_id] target_label: node_id - job_name: 'blackbox-http_2xx-mydomain.com' scrape_interval: 30s metrics_path: /probe params: module: [http_2xx-kamaok] static_configs: - targets: #- http://mydomain.com # Target to probe with http. - https://mydomain.com # Target to probe with https. relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: blackbox-exporter:9115 - job_name: 'blackbox-http_2xx-nexus.mydomain.com' scrape_interval: 30s metrics_path: /probe params: module: [http_2xx-nexus] static_configs: - targets: #- http://nexus.mydomain.com - https://nexus.mydomain.com relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: blackbox-exporter:9115 - job_name: 'blackbox-http_2xx-sonarqube.mydomain.com' scrape_interval: 30s metrics_path: /probe params: module: [http_2xx-sonarqube] static_configs: - targets: #- http://sonarqube.mydomain.com - https://sonarqube.mydomain.com relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: blackbox-exporter:9115 |
Интервал сбора метрик
|
1 |
scrape_interval |
Интервал проверки правил
|
1 |
evaluation_interval |
Метка,используемая для определения сервера, с которого было отправлено оповещение в AlertManager
|
1 2 |
external_labels: monitor: 'prometheus-prod' |
Файлы с правилами
|
1 2 3 4 |
rule_files: - "swarm_node.rules.yml" - "swarm_task.rules.yml" - "swarm_site.rules.yml" |
Удаление ненужных меток-т.е. меток, отправка которых не нужна.
Prometheus будет удалять эти типы меток при отправке push-уведомления в AlertManager, который в свою очередь отправляет сообщений в соответствующий канал информирования(в нашем случае в Slack)
|
1 2 3 4 |
alerting: alert_relabel_configs: - regex: '(container_label_com_amazonaws_ecs_task_arn|container_label_com_amazonaws_ecs_task_definition_version|id|image|container_label_maintainer)' action: labeldrop |
Отправка уведомление в AlertManager при срабатывании правила
|
1 2 3 4 |
alertmanagers: - static_configs: - targets: - alertmanager:9093 |
Снятие метрик/мониторинг самого себя prometheus-ом
|
1 2 3 |
- job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] |
Снятие метрик/мониторинг node-exporter, cadvisor, mongodb-exporter, запущенных в Docker SWARM-кластере
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
- job_name: 'cadvisor' dns_sd_configs: - names: - 'tasks.cadvisor' type: 'A' port: 8080 - job_name: 'node-exporter' dns_sd_configs: - names: - 'tasks.node-exporter' type: 'A' port: 9100 - job_name: 'mongodb-exporter' dns_sd_configs: - names: - 'tasks.mongodb-exporter' type: 'A' port: 9001 |
Снятие метрик/мониторинг node-exporter, cadvisor, mongodb-exporter, запущенных в Docker ECS-кластере
Несколько пояснений
1.Acceess и Secret ключи будут динамически заменены при старте контейнера на указынные в командной строке при запуске мониторинг стека
|
1 2 |
#access_key: <access_key># #secret_key: <secret_key># |
2.Будут мониториться только те EC2-ноды,которые имеют следующий тег(в значениие тега используется regexp)
|
1 |
ecsmonitoring= prometheus-prod |
|
1 2 3 |
- source_labels: [__meta_ec2_tag_ecsmonitoring] regex: prometheus-prod* action: keep |
3.Происходит динамическое изменение меток
По умолчанию в EC2-service-discovery используется внутренний IP-адрес в качестве метки address
Именно по значении метки address и происходит подключение к EC2-нодам к ecs-node-exporter,ecs-advisor,ecs-couchdb-exporter для снятия c них статистики
Поэтому для того,чтобы prometheus смог подключиться к этим экспортерам выполняется переназначение метки address на внешний/публичный IP-адрес EC2-инстанса
|
1 2 3 |
- source_labels: [__meta_ec2_public_ip] target_label: __address__ replacement: '${1}:9999' |
Также добавляем пару дополнительных меток
Instance – со значением равным внешнему доменному имени EC2-инстанса
node_id – идентификатор EC2-инстанса в AWS
|
1 2 3 4 |
- source_labels: [__meta_ec2_public_dns_name] target_label: instance - source_labels: [__meta_ec2_instance_id] target_label: node_id |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
- job_name: 'ecs-node-exporter' ec2_sd_configs: - region: eu-west-1 #access_key: <access_key># #secret_key: <secret_key># refresh_interval: 30s port: 9999 relabel_configs: - source_labels: [__meta_ec2_tag_ecsmonitoring] regex: prometheus-prod* action: keep - source_labels: [__meta_ec2_public_ip] target_label: __address__ replacement: '${1}:9999' - source_labels: [__meta_ec2_public_dns_name] target_label: instance - source_labels: [__meta_ec2_instance_id] target_label: node_id - job_name: 'ecs-cadvisor' ec2_sd_configs: - region: eu-west-1 #access_key: <access_key># #secret_key: <secret_key># refresh_interval: 30s port: 8888 relabel_configs: - source_labels: [__meta_ec2_tag_ecsmonitoring] regex: prometheus-prod* action: keep - source_labels: [__meta_ec2_public_ip] target_label: __address__ replacement: '${1}:8888' - source_labels: [__meta_ec2_public_dns_name] target_label: instance - source_labels: [__meta_ec2_instance_id] target_label: node_id - job_name: 'ecs-couchdb-exporter' ec2_sd_configs: - region: eu-west-1 #access_key: <access_key># #secret_key: <secret_key># refresh_interval: 30s port: 9984 relabel_configs: - source_labels: [__meta_ec2_tag_ecsmonitoring] regex: prometheus-prod* action: keep - source_labels: [__meta_ec2_public_ip] target_label: __address__ replacement: '${1}:9984' - source_labels: [__meta_ec2_public_dns_name] target_label: instance - source_labels: [__meta_ec2_instance_id] target_label: node_id |
Мониторинг сайтов
Модули (http_2xx-kamaok, http_2xx-nexus, http_2xx-sonarqube)
были определены в конфигурационном файле blackbox-экспортера
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
- job_name: 'blackbox-http_2xx-mydomain.com' scrape_interval: 30s metrics_path: /probe params: module: [http_2xx-kamaok] static_configs: - targets: #- http://mydomain.com # Target to probe with http. - https://mydomain.com # Target to probe with https. relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: blackbox-exporter:9115 - job_name: 'blackbox-http_2xx-nexus.mydomain.com' scrape_interval: 30s metrics_path: /probe params: module: [http_2xx-nexus] static_configs: - targets: #- http://nexus.mydomain.com - https://nexus.mydomain.com relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: blackbox-exporter:9115 - job_name: 'blackbox-http_2xx-sonarqube.mydomain.com' scrape_interval: 30s metrics_path: /probe params: module: [http_2xx-sonarqube] static_configs: - targets: #- http://sonarqube.mydomain.com - https://sonarqube.mydomain.com relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: blackbox-exporter:9115 |
Создание пользователя для аутентификации и авторизации в AWS
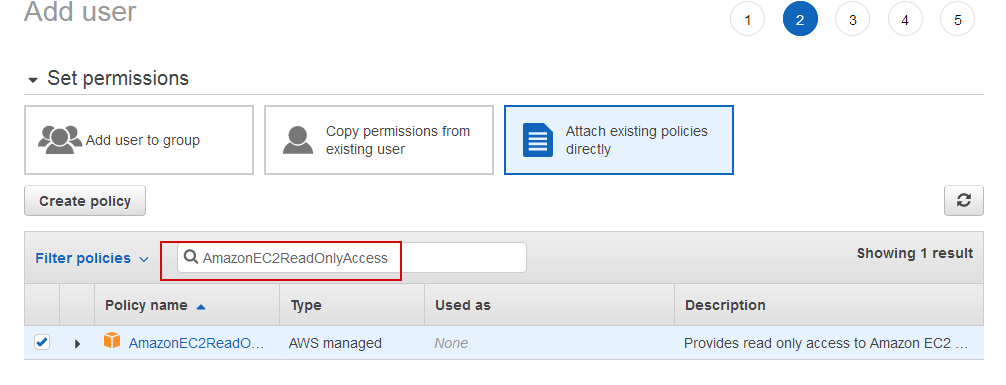
1.Создание пользователя в IAM
|
1 2 3 4 5 6 7 |
AWS->IAM->Users->Add user-> User name->prometheus Access type-> Programmatic access Next permissions->Attach existing policies directly В поиске вбиваем AmazonEC2ReadOnlyAccess и отмечаем выбранную политику Next tags->Next review->Create User Сохраняем access и secret-ключи, которые будут использоваться в конфигурационном файле Prometheus |


2.Добавление тега а ECS EC2-инстансе(например,через AWS console)
|
1 2 |
Key: ecsmonitoring value: prometheus-prod |
3.Настройка Prometheus
Настройка Prometheus для мониторинга только тех нод, у которых стоит тег
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
- job_name: 'ecs-node-exporter' ec2_sd_configs: - region: eu-west-1 #access_key: <access_key># #secret_key: <secret_key># refresh_interval: 30s port: 9999 relabel_configs: - source_labels: [__meta_ec2_tag_ecsmonitoring] regex: prometheus-prod.* action: keep - source_labels: [__meta_ec2_public_ip] target_label: __address__ replacement: '${1}:9999' - source_labels: [__meta_ec2_public_dns_name] target_label: instance - source_labels: [__meta_ec2_instance_id] target_label: node_id - job_name: 'ecs-cadvisor' ec2_sd_configs: - region: eu-west-1 #access_key: <access_key># #secret_key: <secret_key># refresh_interval: 30s port: 8888 relabel_configs: - source_labels: [__meta_ec2_tag_ecsmonitoring] regex: prometheus-prod.* action: keep - source_labels: [__meta_ec2_public_ip] target_label: __address__ replacement: '${1}:8888' - source_labels: [__meta_ec2_public_dns_name] target_label: instance - source_labels: [__meta_ec2_instance_id] target_label: node_id - job_name: 'ecs-couchdb-exporter' ec2_sd_configs: - region: eu-west-1 #access_key: <access_key># #secret_key: <secret_key># refresh_interval: 30s port: 9984 relabel_configs: - source_labels: [__meta_ec2_tag_ecsmonitoring] regex: prometheus-prod.* action: keep - source_labels: [__meta_ec2_public_ip] target_label: __address__ replacement: '${1}:9984' - source_labels: [__meta_ec2_public_dns_name] target_label: instance - source_labels: [__meta_ec2_instance_id] target_label: node_id |
 Опубликовано в рубрике
Опубликовано в рубрике  Метки:
Метки: