 Март 2nd, 2019
Март 2nd, 2019  Evgeniy Kamenev
Evgeniy Kamenev За основу был взят стек мониторинга Prometehus с помощью Prometheus operator отсюда
https://github.com/helm/charts/tree/master/stable/prometheus-operator
https://coreos.com/operators/prometheus/docs/latest/user-guides/getting-started.html
Все параметры, которые необходимо было переопределить указаны в файле custom-values.yaml
Мониторинг стек запускается с помощью Helm-чарта
|
1 |
# helm install --name monitoring-stack stable/prometheus-operator --set grafana.adminPassword="mygrafanapassword" -f custom-values.yaml |
Обновление стека выполняется командой
|
1 |
# helm upgrade monitoring-stack stable/prometheus-operator --set grafana.adminPassword="mygrafanapassword" -f custom-values.yaml |
Установка Helm клиента
https://docs.helm.sh/using_helm/#installing-helm
https://docs.helm.sh/using_helm/
|
1 |
# wget https://storage.googleapis.com/kubernetes-helm/helm-v2.12.3-linux-amd64.tar.gz |
Последняя версия доступная здесь
https://github.com/helm/helm/releases
|
1 |
# tar -zxvf helm-v2.12.3-linux-amd64.tar.gz |
|
1 |
# sudo mv linux-amd64/helm /usr/local/bin/helm |
Проверка текущего контекста,куда будет установлен tiller
|
1 |
# kubectl config current-context |
|
1 |
gke_mydemoproject-123456_europe-west1-b_persistent-disk-tutorial |
Инициализация Helm
Инициализация helm-клиента и установка helm tiller(серверной части)
|
1 |
# helm init |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Creating /home/myusername/.helm Creating /home/myusername/.helm/repository Creating /home/myusername/.helm/repository/cache Creating /home/myusername/.helm/repository/local Creating /home/myusername/.helm/plugins Creating /home/myusername/.helm/starters Creating /home/myusername/.helm/cache/archive Creating /home/myusername/.helm/repository/repositories.yaml Adding stable repo with URL: https://kubernetes-charts.storage.googleapis.com Adding local repo with URL: http://127.0.0.1:8879/charts $HELM_HOME has been configured at /home/myusername/.helm. Tiller (the Helm server-side component) has been installed into your Kubernetes Cluster. Please note: by default, Tiller is deployed with an insecure 'allow unauthenticated users' policy. To prevent this, run `helm init` with the --tiller-tls-verify flag. For more information on securing your installation see: https://docs.helm.sh/using_helm/#securing-your-helm-installation Happy Helming! |
После чего в namespace kube-system должен появиться tiller pod
|
1 |
# kubectl get pods --namespace kube-system | grep tiller |
|
1 |
tiller-deploy-666576cc98-4ljfg 1/1 Running 0 5m |
т.е. tiller server запускается как Pod в namespace kube-system
Предоставление Tiller-у необходимых привилегий для создания/изменения/удаления ресурсов в кластере
Создаем serviceaccount, привязываем к нему роль cluster-admin, патчим созданный deployment tiller-deploy
https://github.com/fnproject/fn-helm/issues/21
|
1 |
# kubectl create serviceaccount --namespace kube-system tiller |
|
1 |
# kubectl create clusterrolebinding tiller-cluster-rule --clusterrole=cluster-admin –serviceaccount=kube-system:tiller |
Роль cluster-admin создается по умолчанию в Kubernetes-кластере, поэтому отдельное ее описание не требуется
|
1 |
# kubectl patch deploy --namespace kube-system tiller-deploy -p '{"spec":{"template":{"spec":{"serviceAccount":"tiller"}}}}' |
Проверяем налииче созданного serviceaccount-а
|
1 |
# kubectl get serviceaccount -n kube-system | grep -E 'NAME|tiller' |
|
1 2 |
NAME SECRETS AGE tiller 1 1m |
Проверяем наличие привязанной/прикрепленной роли
|
1 |
# kubectl get clusterrolebinding | grep -E 'NAME|tiller' |
|
1 2 |
NAME AGE tiller-cluster-rule 36s |
Пропатченного deployment-а tiller-deploy
|
1 |
# kubectl get deployment tiller-deploy -n kube-system -o yaml | grep -i serviceaccount |
|
1 2 3 |
automountServiceAccountToken: true serviceAccount: tiller serviceAccountName: tiller |
Альтернативным вариантом может быть выполнение инициализации helm с указанием serviceaccount
https://helm.sh/docs/using_helm/#tiller-and-role-based-access-control
Например, создаем serviceaccount,role binding
|
1 |
# nano rbac-config.yaml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
apiVersion: v1 kind: ServiceAccount metadata: name: tiller namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: tiller roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: tiller namespace: kube-system |
|
1 |
# kubectl create -f rbac-config.yaml |
Выполненние инициализации Helm с созданным предыдущей командой serviceaccount-ом
|
1 |
# helm init --service-account tiller |
Prometheus custom rules
По умолчанию одно из правил Prometheus (CPUThrottlingHigh)имеет низкое пороговое значение параметра, которое отвечает за срабатывание правила(25%), в результате чего, например, дефолтные служебные поды в namespace kube-system, а также некоторые поды из мониторинг стека превышают значение этого параметра(25%) и срабатывает оповещение
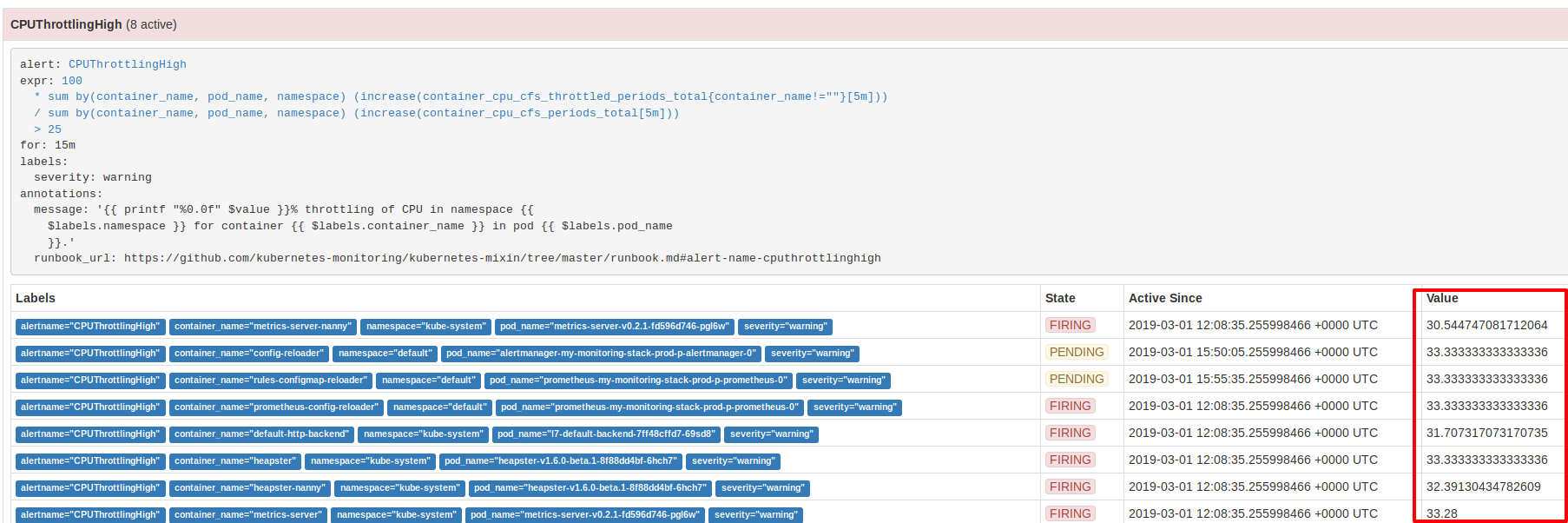
В связи с этим я отключаю оповещение для этого правила в AlertManager(через WEB-интерфейс AlertManager-а на вкладке Silence) и создаю отдельное правило, которые имеет более высокий порог срабатывания(50%)
В этом правиле важно иметь метки с такими именами/значениями
|
1 2 |
app: prometheus-operator release: <release_name> |
Имя релиза – это имя указанное в параметре —name при запуске мониторинг стека(в данном случае monitoring-stack)
|
1 |
# cat custom-rules.yaml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: app: prometheus-operator release: monitoring-stack name: surname name: my-custom-rules-file namespace: default spec: groups: - name: kubernetes-resources-custom rules: - alert: Custom-CPUThrottlingHigh annotations: message: '{{ printf "%0.0f" $value }}% throttling of CPU in namespace {{ $labels.namespace }} for container {{ $labels.container_name }} in pod {{ $labels.pod_name }}.' runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-cputhrottlinghigh expr: |- 100 * sum(increase(container_cpu_cfs_throttled_periods_total{container_name!="", }[5m])) by (container_name, pod_name, namespace) / sum(increase(container_cpu_cfs_periods_total{}[5m])) by (container_name, pod_name, namespace) > 50 for: 15m labels: severity: warning |
Создаем кастомное правила для Prometheus
|
1 |
# kubectl apply -f custom-rules.yaml |
Альтернативной возможностью по добавлению своих правил для Prometheus является добавление их в параметр additionalPrometheusRules в файл custom-values.yaml
В данном примере эти строки я закомментировал.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#additionalPrometheusRules: # - name: my-custom-rules-file-2 # groups: # - name: kubernetes-resources-custom2 # rules: # - alert: Custom-CPUThrottlingHigh2 # annotations: # message: '{{`{{ printf "%0.0f" $value }}`}}% throttling of CPU in namespace {{`{{ $labels.namespace }}`}} for container {{`{{ $labels.container_name }}`}} in pod {{`{{ $labels.pod_name }}`}}.' # runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-cputhrottlinghigh # expr: |- # 100 * sum(increase(container_cpu_cfs_throttled_periods_total{container_name!="", }[5m])) by (container_name, pod_name, namespace) # / # sum(increase(container_cpu_cfs_periods_total{}[5m])) by (container_name, pod_name, namespace) # > 55 # for: 15m # labels: # severity: warning |
Файл с пользовательскими настройками/значениями имеет вид
|
1 |
# cat custom-values.yaml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
# Depending on which DNS solution you have installed in your cluster enable the right exporter coreDns: enabled: false kubeDns: enabled: true #additionalPrometheusRules: # - name: my-custom-rules-file-2 # groups: # - name: kubernetes-resources-custom2 # rules: # - alert: Custom-CPUThrottlingHigh2 # annotations: # message: '{{`{{ printf "%0.0f" $value }}`}}% throttling of CPU in namespace {{`{{ $labels.namespace }}`}} for container {{`{{ $labels.container_name }}`}} in pod {{`{{ $labels.pod_name }}`}}.' # runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-cputhrottlinghigh # expr: |- # 100 * sum(increase(container_cpu_cfs_throttled_periods_total{container_name!="", }[5m])) by (container_name, pod_name, namespace) # / # sum(increase(container_cpu_cfs_periods_total{}[5m])) by (container_name, pod_name, namespace) # > 55 # for: 15m # labels: # severity: warning alertmanager: config: global: resolve_timeout: 5m route: group_by: ['job'] group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: 'slack' routes: - match: alertname: Watchdog receiver: 'slack' receivers: - name: 'slack' slack_configs: - send_resolved: true api_url: 'https://hooks.slack.com/services/my-slack-token' channel: '#prometheus' username: alertmanager title: '{{ template "custom_title" . }}' text: '{{ template "custom_slack_message" . }}' templates: - '/etc/alertmanager/config/template_alert.tmpl' # - '*.tmpl' templateFiles: template_alert.tmpl: |- {{ define "__single_message_title" }}{{ range .Alerts.Firing }}{{ .Labels.alertname }} @ {{ .Annotations.message }}{{ end }}{{ range .Alerts.Resolved }}{{ .Labels.alertname }} @ {{ .Annotations.message }}{{ end }}{{ end }} {{ define "custom_title" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ if or (and (eq (len .Alerts.Firing) 1) (eq (len .Alerts.Resolved) 0)) (and (eq (len .Alerts.Firing) 0) (eq (len .Alerts.Resolved) 1)) }}{{ template "__single_message_title" . }}{{ end }}{{ end }} {{ define "custom_slack_message" }} {{ if or (and (eq (len .Alerts.Firing) 1) (eq (len .Alerts.Resolved) 0)) (and (eq (len .Alerts.Firing) 0) (eq (len .Alerts.Resolved) 1)) }} {{ range .Alerts.Firing }}{{ .Annotations.message }}{{ end }}{{ range .Alerts.Resolved }}{{ .Annotations.message }}{{ end }} {{ else }} {{ if gt (len .Alerts.Firing) 0 }} *Alerts Firing:* {{ range .Alerts.Firing }}- {{ .Annotations.message }}: {{ .Annotations.runbook_url }} {{ end }}{{ end }} {{ if gt (len .Alerts.Resolved) 0 }} *Alerts Resolved:* {{ range .Alerts.Resolved }}- {{ .Annotations.message }}: {{ .Annotations.runbook_url }} {{ end }}{{ end }} {{ end }} {{ end }} alertmanagerSpec: storage: volumeClaimTemplate: spec: accessModes: ["ReadWriteOnce"] resources: requests: storage: 1Gi prometheus: prometheusSpec: retention: 30d resources: requests: memory: 512Mi limits: memory: 1024Mi storageSpec: volumeClaimTemplate: spec: accessModes: ["ReadWriteOnce"] resources: requests: storage: 10Gi grafana: service: loadBalancerIP: "34.76.118.37" type: LoadBalancer persistence: enabled: true accessModes: ["ReadWriteOnce"] size: 10Gi |
В зависимости от того, какое DNS-решение используется в кластере CoreDNS или KubeDNS
необходимо включить/отключить соотвествующий экспортер
В данном случае
|
1 2 3 4 5 |
coreDns: enabled: false kubeDns: enabled: true |
Настройка AlertManager
Изменяем конфигурцию AlertManager-a, настраивая отправку оповещений в Slack
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
alertmanager: config: global: resolve_timeout: 5m route: group_by: ['job'] group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: 'slack' routes: - match: alertname: Watchdog receiver: 'slack' receivers: - name: 'slack' slack_configs: - send_resolved: true api_url: 'https://hooks.slack.com/services/my-slack-token' channel: '#prometheus' username: alertmanager |
2.Настраиваем AlertManager на использование кастомных шаблонов для отправки уведомлений
|
1 2 |
title: '{{ template "custom_title" . }}' text: '{{ template "custom_slack_message" . }}' |
Создаем отдельный файл с шаблоном template_alert.tmpl, в котором описаны вышеуказанные шаблоны
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
templateFiles: template_alert.tmpl: |- {{ define "__single_message_title" }}{{ range .Alerts.Firing }}{{ .Labels.alertname }} @ {{ .Annotations.message }}{{ end }}{{ range .Alerts.Resolved }}{{ .Labels.alertname }} @ {{ .Annotations.message }}{{ end }}{{ end }} {{ define "custom_title" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ if or (and (eq (len .Alerts.Firing) 1) (eq (len .Alerts.Resolved) 0)) (and (eq (len .Alerts.Firing) 0) (eq (len .Alerts.Resolved) 1)) }}{{ template "__single_message_title" . }}{{ end }}{{ end }} {{ define "custom_slack_message" }} {{ if or (and (eq (len .Alerts.Firing) 1) (eq (len .Alerts.Resolved) 0)) (and (eq (len .Alerts.Firing) 0) (eq (len .Alerts.Resolved) 1)) }} {{ range .Alerts.Firing }}{{ .Annotations.message }}{{ end }}{{ range .Alerts.Resolved }}{{ .Annotations.message }}{{ end }} {{ else }} {{ if gt (len .Alerts.Firing) 0 }} *Alerts Firing:* {{ range .Alerts.Firing }}- {{ .Annotations.message }}: {{ .Annotations.runbook_url }} {{ end }}{{ end }} {{ if gt (len .Alerts.Resolved) 0 }} *Alerts Resolved:* {{ range .Alerts.Resolved }}- {{ .Annotations.message }}: {{ .Annotations.runbook_url }} {{ end }}{{ end }} {{ end }} {{ end }} |
Создаем Persistent Volume Claim для хранения Alertmanager-ом своих данных(каталога /alertmanager( в нем хранятся, например, настройки silence, сделанные через WEB-интерфейс AlertManager)
|
1 2 3 4 5 6 7 8 |
alertmanagerSpec: storage: volumeClaimTemplate: spec: accessModes: ["ReadWriteOnce"] resources: requests: storage: 1Gi |
Настройка Prometheus
Переопределям следующе параметры
— время хранения данных(параметр retention)
— ресурсы, выделяемые для пода
— cоздаем Persistent Volume Claim для хранения Prometheus-ом своих данных(каталога /prometheus)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
prometheus: prometheusSpec: retention: 31d resources: requests: memory: 512Mi limits: memory: 1024Mi storageSpec: volumeClaimTemplate: spec: accessModes: ["ReadWriteOnce"] resources: requests: storage: 10Gi |
Настройка Grafana
Переопределям следующе параметры
— тип сервиса с дефолтного ClusterIP на Loadbalancer
— указываем статический IP-адрес(полученный у облачного провайдера), на котором будет слушать запросы Loadabalancer
На этот IP-адрес необходимо также настроить DNS-имя, которое используется для доступа к Grafanе (например, grafana.mydomain.com)
|
1 2 3 |
service: loadBalancerIP: "34.76.112.31" type: LoadBalancer |
Определяем том для хранения Grafan-ой своих данных(каталога /var/lib/grafana, в котором хранятся база данных Grafana и плагины)
|
1 2 3 4 |
persistence: enabled: true accessModes: ["ReadWriteOnce"] size: 10Gi |
Для доступа к и Prometheus и AlertManager (оба сервиса по умолчанию не имеют авторизации, поэтому нежелательно выставлять их наружу)используем port-forward
Prometheus
|
1 |
# kubectl port-forward prometheus-monitoring-stack-p-prometheus-0 9090:9090 |
Доступ к Prometheus
|
1 |
http://localhost:9090 |
AlertManager
|
1 |
# kubectl port-forward alertmanager-monitoring-stack-p-alertmanager-0 9093:9093 |
Доступ к AlertManager
|
1 |
http://localhost:9093 |
Просмотр метрик с Kube-state-metrics и Node-exporter
Kube-state-metrics
|
1 |
# kubectl port-forward monitoring-stack-kube-state-metrics-66558d8b6c-mq4bh 8080:8080 |
Доступ к Kube-state-metrics
|
1 |
http://localhost:8080 |
Node-exporter
|
1 |
# kubectl port-forward monitoring-stack-prometheus-node-exporter-pgf8w 9100:9100 |
Доступ к Node-exporter
|
1 |
http://localhost:9100 |
Grafana имеет встроенную авторизацию через логин/пароль. Поэтому выставим ее наружу через Service c типом LoadBalancer
Также для того, чтобы после рестарта LoadBalancera IP-адрес его не изменялся, зарезервируем у провайдера и будем использовать фиксированный IP-адрес
Например, получим у Google Cloud-провайдера фиксированный IP-адрес
https://cloud.google.com/kubernetes-engine/docs/tutorials/configuring-domain-name-static-ip
|
1 |
# gcloud compute addresses create grafana-ip-lb --region europe-west1 |
|
1 |
Created [https://www.googleapis.com/compute/v1/projects/mydemoproject-123456/regions/europe-west1/addresses/grafana-ip-lb]. |
|
1 |
# gcloud compute addresses list |
|
1 2 3 |
NAME ADDRESS/RANGE TYPE PURPOSE NETWORK REGION SUBNET STATUS grafana-ip-lb 34.76.112.31 europe-west1 RESERVED |
![]()
Настройка service для Grafana имеет вид:
|
1 2 3 4 |
grafana: service: loadBalancerIP: "34.76.112.31" type: LoadBalancerr |
Google Cloud создает TCP/UDP LoadBalancer, который также умеет работать с HTTP запросами, но не умееет работать с HTTPS-трафиком.Если необходимо настраивать Grafana на использование HTTPS, тогда необходимо создавать Ingress ресурс, а тип сервиса устанавливать в NodePort( этот вариант рассмотрен в конце статьи)
https://cloud.google.com/load-balancing/docs/network/
https://cloud.google.com/kubernetes-engine/docs/tutorials/http-balancer#background
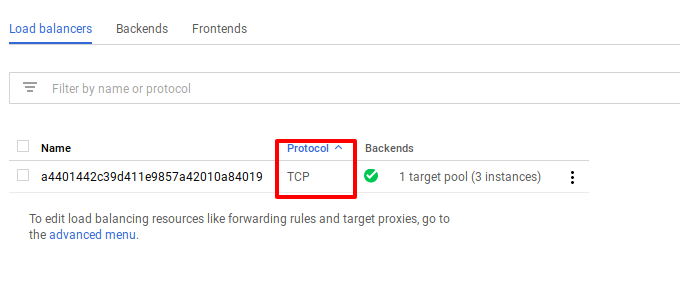
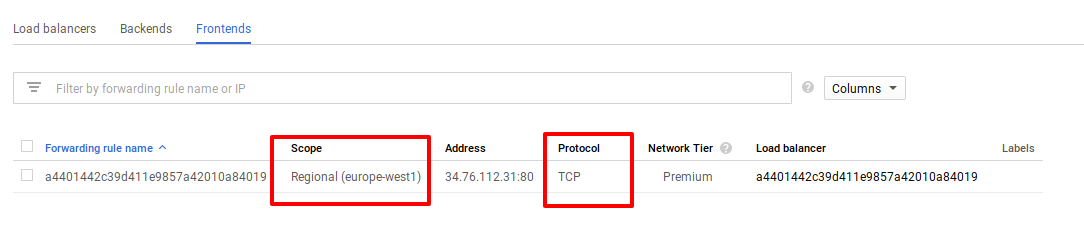
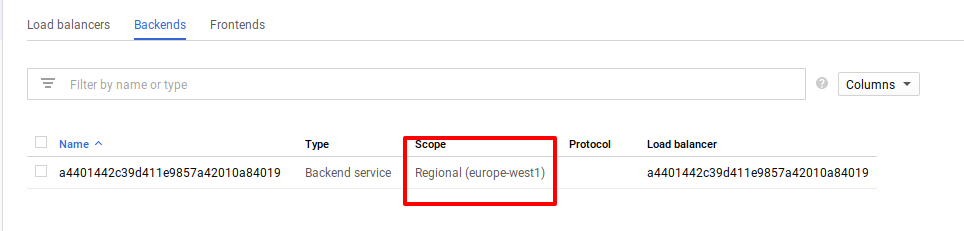
Проверяем service для Grafana
|
1 |
# kubectl get svc | grep grafana |
|
1 2 |
monitoring-stack-grafana LoadBalancer 10.43.241.133 34.76.112.31 80:31571/TCP 3d |
Grafana запускается как Deplyment, а Prometheus и AlertManager – как StatefulSet
|
1 |
# kubectl get deployment |
|
1 2 |
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE monitoring-stack-grafana 1 1 1 1 44m |
|
1 |
# kubectl get statefulset |
|
1 2 3 |
NAME DESIRED CURRENT AGE alertmanager-monitoring-stack-prometheu-alertmanager 1 1 44m prometheus-monitoring-stack-prometheu-prometheus 1 1 44m |
|
1 |
# kubectl get pod | grep -E 'alertmanager|grafana|^prometheus' |
|
1 2 3 |
alertmanager-monitoring-stack-prometheu-alertmanager-0 2/2 Running 0 45m monitoring-stack-grafana-5f485c6bdf-tpq7g 3/3 Running 1 46m prometheus-monitoring-stack-prometheu-prometheus-0 3/3 Running 1 45m |
Описание назначения контейнеров, которые запускаются внутри одного пода для AlertManager, Prometheus, Grafana
В Pod-е c AlertManager-ом запускается два контейнера
|
1 2 |
- контейнер с непосредственно самим AlertManager с именем контейнера alertmanager - вспомогательный контейнере с именем контейнера config-reloader, который следит за изменением конфигурационного файла AlertManager-а(который имеет сущность/ресурс ConfigMap) и посылает команду на AlertManager (для того,чтобы AlertManager перечитал свой конфигурационный файл) при изменении конф.файла AlertManager-а |
|
1 |
# kubectl logs -f -c config-reloader alertmanager-monitoring-stack-prometheu-alertmanager-0 |
|
1 2 |
2019/03/01 10:14:41 config map updated 2019/03/01 10:14:42 successfully triggered reload |
Аналогично с Prometheus
В поде с Prometheus запущено 3 контейнера
|
1 2 3 |
- контейнер с непосредственно самим Prometheus с именем контейнера prometheus - контейнер с именем rules-configmap-reloader для мониторинга изменений правил Prometehus и отправки команды/сигнала на контейнер с Prometheus при изменении правил - контейнер с именем prometheus-config-reloader для мониторинга изменений конфигуационого файла Prometehus и отправки команды/сигнала на контейнер с Prometheus при изменении конф.файла |
Например, логи контйнера rules-configmap-reloader
|
1 |
# kubectl logs -f -c rules-configmap-reloader prometheus-monitoring-stack-p-prometheus-0 |
|
1 2 |
2019/02/28 13:58:35 config map updated 2019/02/28 13:58:35 successfully triggered reload |
В поде с Grafana запущено 3 контейнера
|
1 2 3 |
- контейнер с непосредственно самой Grafana с именем контейнера grafana - контейнер с именем grafana-sc-datasources для динамической настройки источников данных(Data Source), с которых Grafana может собирать данные - контейнер с именем grafana-sc-dashboard для динамической настройки dashboard-ов доступных в Grafana |
Проверка того, как поды AlertManager, Prometheus, Grafana используют Persistent Volume
|
1 |
# kubectl describe pod alertmanager-monitoring-stack-prometheu-alertmanager-0 | less |
|
1 2 3 4 5 6 7 8 9 10 |
... Mounts: /alertmanager from alertmanager-monitoring-stack-prometheu-alertmanager-db (rw) ... Volumes: alertmanager-monitoring-stack-prometheu-alertmanager-db: Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace) ClaimName: alertmanager-monitoring-stack-prometheu-alertmanager-db-alertmanager-monitoring-stack-prometheu-alertmanager-0 ReadOnly: false ... |
|
1 |
# kubectl describe pod prometheus-monitoring-stack-prometheu-prometheus-0 |
|
1 2 3 4 5 6 7 8 9 10 |
... Mounts: /prometheus from prometheus-monitoring-stack-prometheu-prometheus-db (rw) ... Volumes: prometheus-monitoring-stack-prometheu-prometheus-db: Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace) ClaimName: prometheus-monitoring-stack-prometheu-prometheus-db-prometheus-monitoring-stack-prometheu-prometheus-0 ReadOnly: false ... |
|
1 |
# kubectl describe pod monitoring-stack-grafana-5f485c6bdf-tpq7g | less |
|
1 2 3 4 5 6 7 8 9 10 |
... Mounts: /var/lib/grafana from storage (rw) ... Volumes: storage: Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace) ClaimName: monitoring-stack-grafana ReadOnly: false ... |
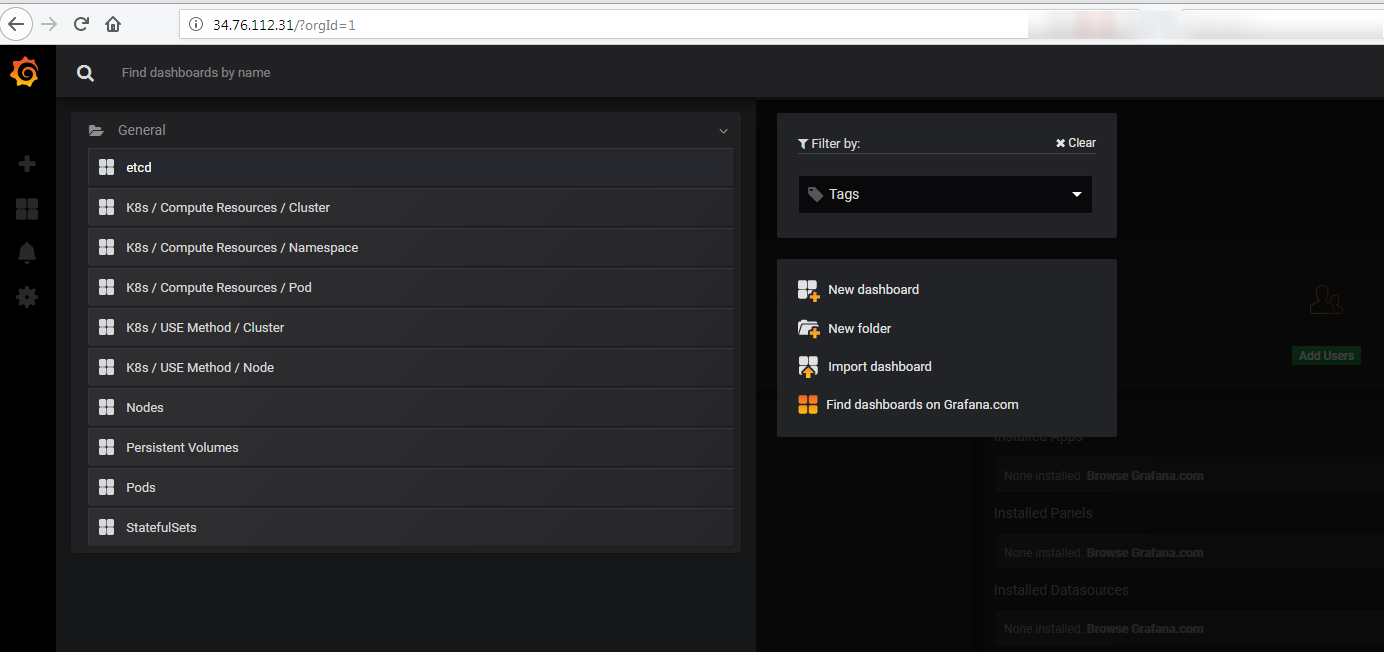
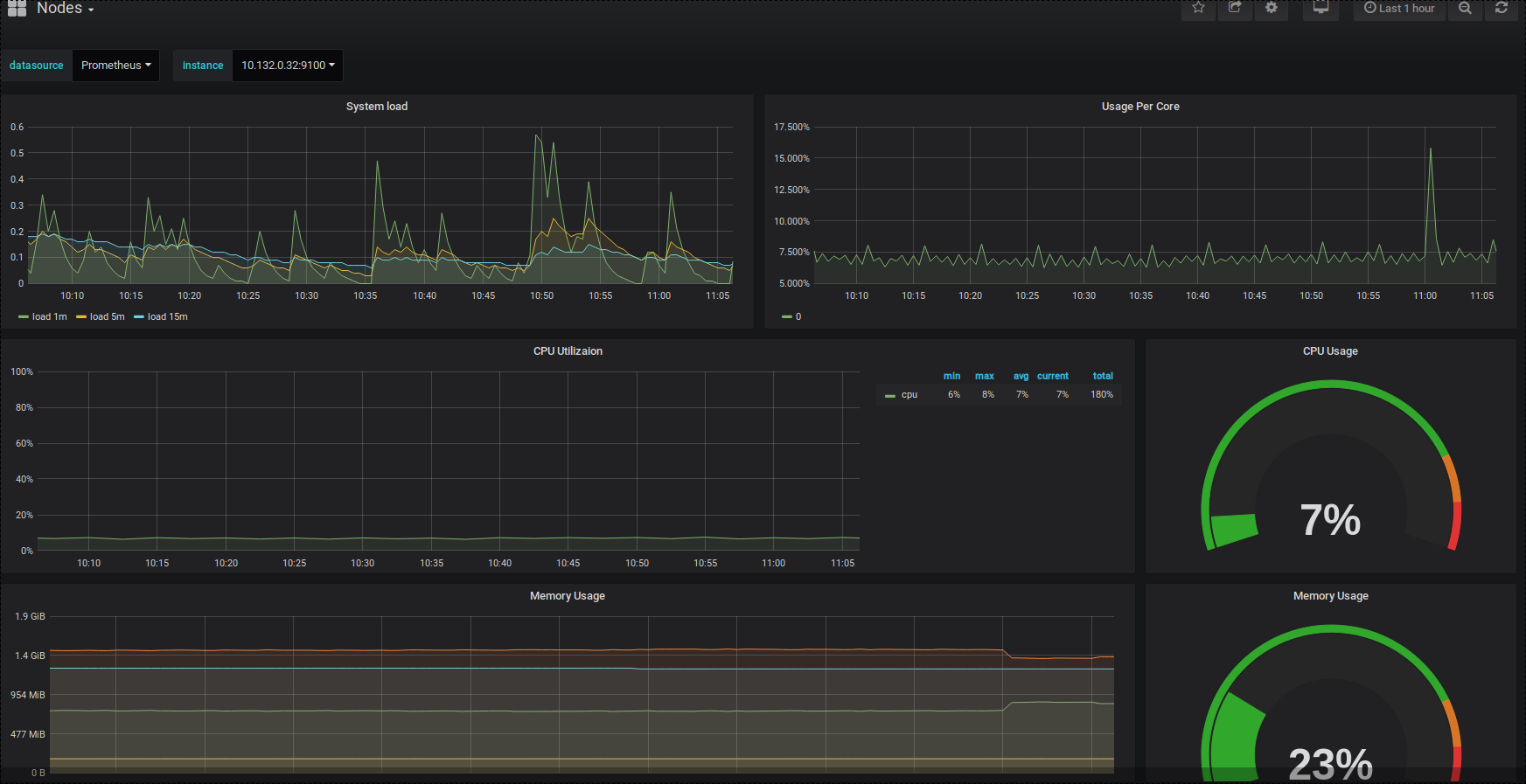
Grafana
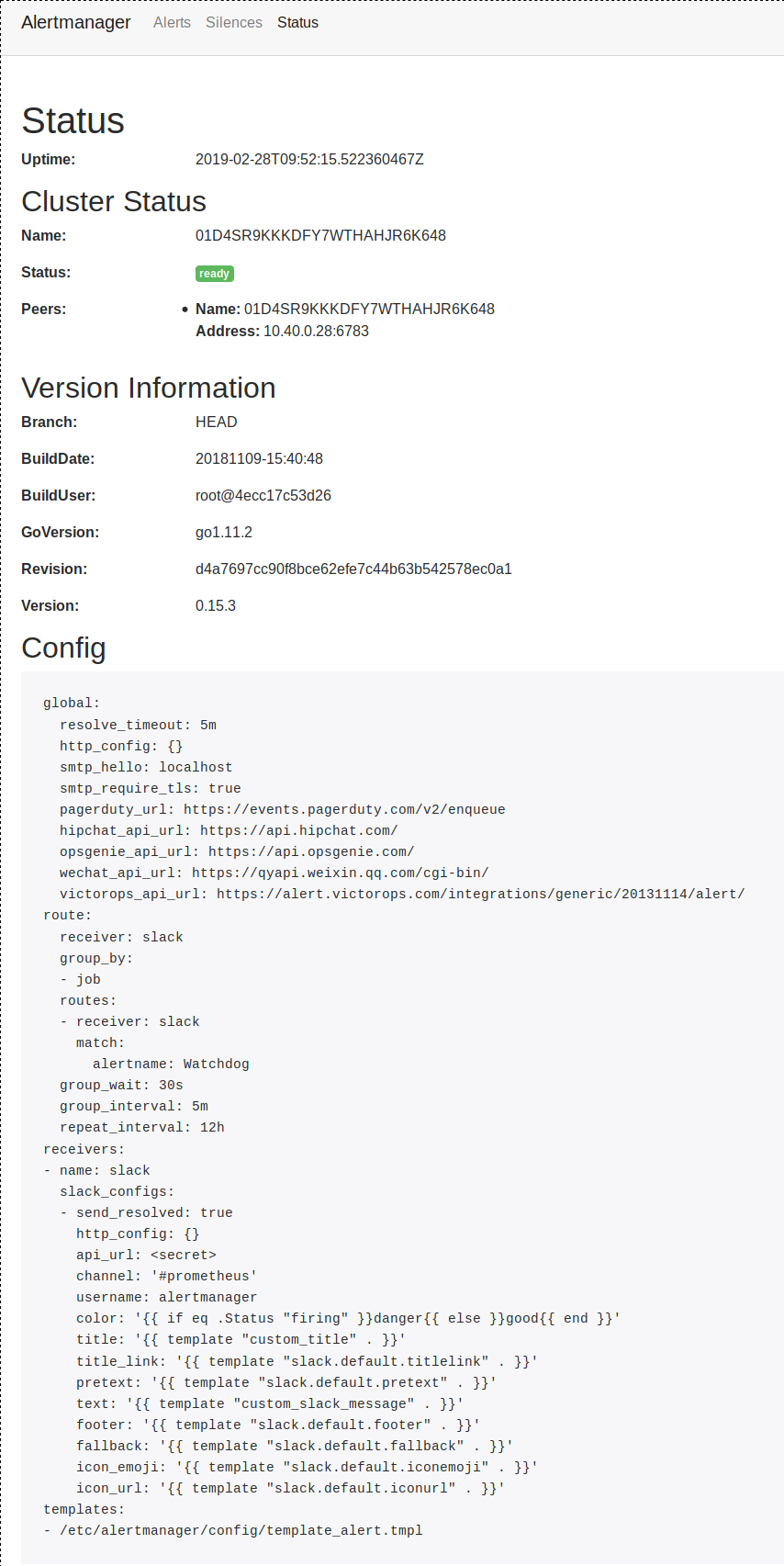
AlertManager
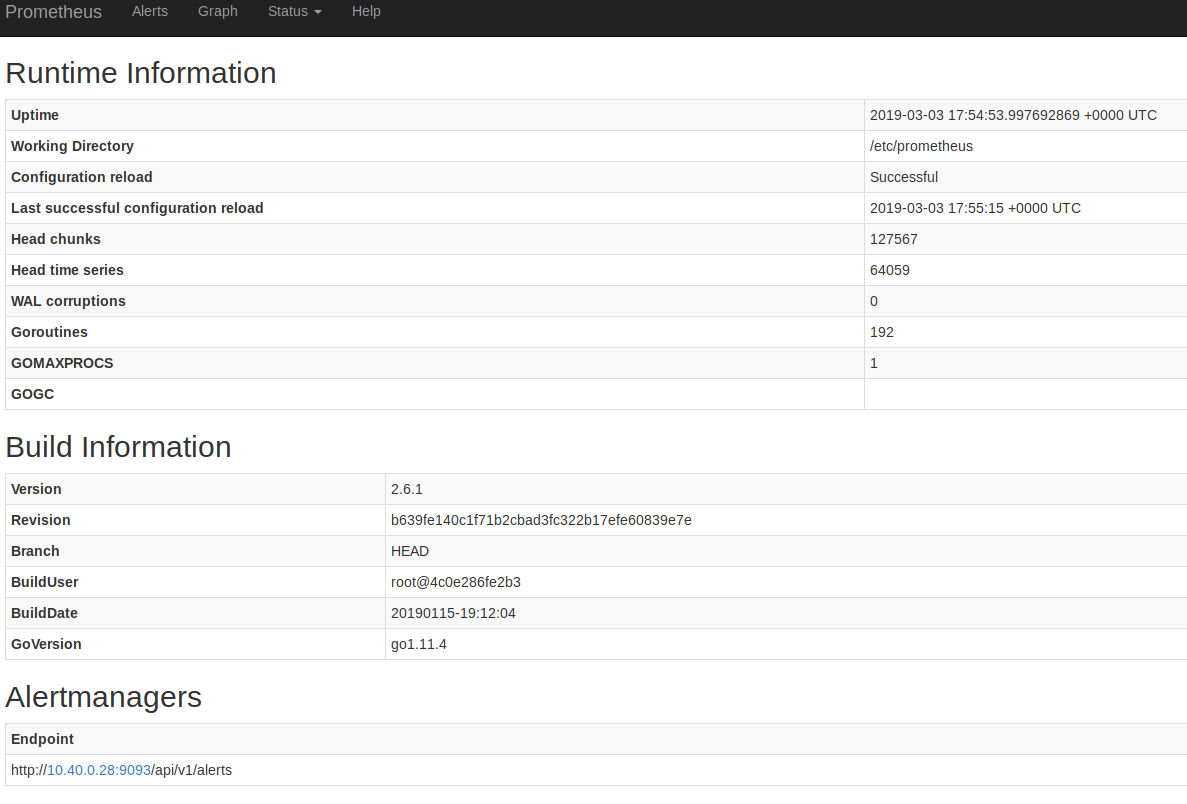
Prometheus
Увеличение размера/расширение Persistent Volume для Prometheus(используемого для хранения своих данных time-series database)
Для расширения тома, используемого подом необходимо
1.Изменить размер тома,указанного в PVC, который связан с PV, монтируемым/используемым подом
2.Расширить файловую систему(выполняется автоматически средствами Kubernetes при удалении пода вручную и его автоматическом перезапуске реплика контроллером)
Например, увеличим размер тома с 10Gb до 50Gb
|
1 |
# kubectl get pvc,pv |
|
1 2 3 4 5 6 |
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE persistentvolumeclaim/prometheus-monitoring-stack-prometheu-prometheus-db-prometheus-monitoring-stack-prometheu-prometheus-0 Bound pvc-9a4d796c-3b6b-11e9-a130-42010a8e002e 10Gi RWO standard 18h NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE persistentvolume/pvc-9a4d796c-3b6b-11e9-a130-42010a8e002e 10Gi RWO Delete Bound default/prometheus-monitoring-stack-prometheu-prometheus-db-prometheus-monitoring-stack-prometheu-prometheus-0 |
1.Изменение размера тома,указанного в PVC
Расширяем размер тома с 10 до 50 Gb в ресурсе PVC
Для этого изменим значение параметра
|
1 2 3 |
resources: requests: storage: 10Gi |
С 10 на 50
|
1 |
# kubectl edit pvc prometheus-monitoring-stack-prometheu-prometheus-db-prometheus-monitoring-stack-prometheu-prometheus-0 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
apiVersion: v1 kind: PersistentVolumeClaim metadata: annotations: pv.kubernetes.io/bind-completed: "yes" pv.kubernetes.io/bound-by-controller: "yes" volume.beta.kubernetes.io/storage-provisioner: kubernetes.io/gce-pd creationTimestamp: "2019-02-28T15:14:54Z" finalizers: - kubernetes.io/pvc-protection labels: app: prometheus prometheus: monitoring-stack-prometheu-prometheus name: prometheus-monitoring-stack-prometheu-prometheus-db-prometheus-monitoring-stack-prometheu-prometheus-0 namespace: default resourceVersion: "2636513" selfLink: /api/v1/namespaces/default/persistentvolumeclaims/prometheus-monitoring-stack-prometheu-prometheus-db-prometheus-monitoring-stack-prometheu-prometheus-0 uid: 9a4d796c-3b6b-11e9-a130-42010a8e002e spec: accessModes: - ReadWriteOnce resources: requests: storage: 50Gi storageClassName: standard volumeName: pvc-9a4d796c-3b6b-11e9-a130-42010a8e002e status: …… |
После этого необходимо проверить наличие записи в ресурсе PVC,
|
1 |
type: FileSystemResizePending |
означающей ожидание расширения файловой системы
|
1 |
# kubectl get pvc prometheus-monitoring-stack-prometheu-prometheus-db-prometheus-monitoring-stack-prometheu-prometheus-0 -o yaml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
apiVersion: v1 kind: PersistentVolumeClaim metadata: annotations: pv.kubernetes.io/bind-completed: "yes" pv.kubernetes.io/bound-by-controller: "yes" volume.beta.kubernetes.io/storage-provisioner: kubernetes.io/gce-pd creationTimestamp: "2019-02-28T15:14:54Z" finalizers: - kubernetes.io/pvc-protection labels: app: prometheus prometheus: monitoring-stack-prometheu-prometheus name: prometheus-monitoring-stack-prometheu-prometheus-db-prometheus-monitoring-stack-prometheu-prometheus-0 namespace: default resourceVersion: "2636513" selfLink: /api/v1/namespaces/default/persistentvolumeclaims/prometheus-monitoring-stack-prometheu-prometheus-db-prometheus-monitoring-stack-prometheu-prometheus-0 uid: 9a4d796c-3b6b-11e9-a130-42010a8e002e spec: accessModes: - ReadWriteOnce resources: requests: storage: 50Gi storageClassName: standard volumeName: pvc-9a4d796c-3b6b-11e9-a130-42010a8e002e status: accessModes: - ReadWriteOnce capacity: storage: 10Gi conditions: - lastProbeTime: null lastTransitionTime: "2019-03-01T09:29:17Z" message: Waiting for user to (re-)start a pod to finish file system resize of volume on node. status: "True" type: FileSystemResizePending phase: Bound |
2.Перезапускаем Pod для автоматического расширения файловой системы(альтернативным вариантом перезапуску пода является scaling down и scaling up)
Удаляем Pod,который испоьзует расширяемый том
|
1 |
# kubectl delete pod prometheus-monitoring-stack-prometheu-prometheus-0 |
После перезапуска Poda проверяем размер PVC, PV
|
1 |
# kubectl get pvc | grep prometheus |
|
1 |
prometheus-monitoring-stack-prometheu-prometheus-db-prometheus-monitoring-stack-prometheu-prometheus-0 Bound pvc-9a4d796c-3b6b-11e9-a130-42010a8e002e 50Gi RWO standard 18h |
|
1 |
# kubectl get pv | grep prometheus |
|
1 |
pvc-9a4d796c-3b6b-11e9-a130-42010a8e002e 50Gi RWO Delete Bound default/prometheus-monitoring-stack-prometheu-prometheus-db-prometheus-monitoring-stack-prometheu-prometheus-0 standard 18h |
Настройка Grafana на поддержку SSL
Для предоставления снаружи доступа к приложению, развернутого на Google Kubernetes Engine можно воспользоваться одним из следующих способов:
— Используя Service, которая создает TCP Network Load Balancer, работающий с региональными IP-адресами(что было реализовано выше). В таком случае необходимо создавать региональный IP-адрес. Глобальные IP-адреса работают только с типом ресурса Ingress
— Используя Ingress, который создает HTTP(S) Load Balancer и поддерживает глобальные IP-адреса.
Чтобы узнать о достоинствах и недостатках каждого метода, обратитесь к руководству по HTTP Load Balancing tutorial
При создании ресурса типа Ingress GKE ingress контроллер создает и настраивает балансировщик нагрузки HTTP(S) в соответствии с информацией в Ingress и связанных service-ов(service name и service port выступают в качестве backend-ов, на которые перенаправляются входящие на Ingress запросы). Кроме того, балансировщик нагрузки получает внешний IP-адрес, который можно связать с доменным именем.
Алгоритм действий состоит из следущих шагов
1.Создание ресурса Secret с типом tls в том же namespace, где запущен и сам Pod
2.Получение у облачного провайдера глобального статического внешнего IP-адреса, который будет использоваться Ingress-ом
3.Настройка Service и Ingress для Grafana
1.Создание вручную Secret с типом tls в том же namespace, где запущен и сам Pod с Grafana(в даном случае в namespace defaut)
|
1 |
# kubectl create secret tls grafana-tls --cert=/home/SSL/grafana.mydomain.com/cert.pem --key=/home/SSL/grafana.mydomain.com/privkey.pem |
|
1 |
secret/grafana-tls created |
|
1 |
# kubectl get secret grafana-tls -o wide |
|
1 2 |
NAME TYPE DATA AGE grafana-tls kubernetes.io/tls 2 23m |
Просмотр секрета
|
1 |
# kubectl get secret grafana-tls -o yaml |
2.Получение у облачного провайдера глобального статического внешнего IP-адреса, который будет использоваться Ingress-ом
Создание статического ГЛОБАЛЬНОГО IP-адреса для Ingress
|
1 |
# gcloud compute addresses create grafana-ip-ingress --global |
|
1 |
# gcloud compute addresses list |
|
1 2 |
NAME ADDRESS/RANGE TYPE PURPOSE NETWORK REGION SUBNET STATUS grafana-ip-ingress 34.95.109.1 RESERVED |
|
1 |
# gcloud compute addresses describe grafana-ip-ingress --global |
|
1 2 3 4 5 6 7 8 9 10 |
address: 34.95.109.1 creationTimestamp: '2019-03-01T03:27:13.858-08:00' description: Static IP address for Grafana id: '5221734495217297918' ipVersion: IPV4 kind: compute#address name: grafana-ip-ingress networkTier: PREMIUM selfLink: https://www.googleapis.com/compute/v1/projects/mydemoproject-231415/global/addresses/grafana-ip status: RESERVED |
3.Настройка Service и Ingress для Grafana
— Тип Service необходимо изменить на NodePort
— включить и настроить Ingress
|
1 |
# nano custom-values.yaml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
service: type: NodePort ingress: enabled: true annotations: #kubernetes.io/ingress.global-static-ip-name: grafana-ip-lb kubernetes.io/ingress.global-static-ip-name: grafana-ip-ingress #kubernetes.io/ingress.allow-http: "false" labels: {} ## Hostnames. ## Must be provided if Ingress is enable. hosts: - grafana.mydomain.com ## TLS configuration for prometheus Ingress ## Secret must be manually created in the namespace tls: - secretName: grafana-tls hosts: - grafana.mydomain.com |
Обновление мониторинг стека и проверка доступности Grafana по HTTPS-протоколу
|
1 |
# helm upgrade monitoring-stack stable/prometheus-operator --set grafana.adminPassword="mygrafanapassword" -f custom-values.yaml |
В DNS настраиваем соответствие доменного имени, на котором доступна Grafana, и IP-адреса, на котором настроен Ingress
Либо для тесторования через правку локального hosts-файла
В данном случае
|
1 |
34.95.109.1 grafana.mydomain.com |
После чего в браузере проверяем доступность Grafana через HTTPS
Удаление стека
|
1 |
# helm delete --purge monitoring-stack |
Удаление custom resource definition(CRD)
|
1 |
# kubectl delete --ignore-not-found customresourcedefinitions prometheuses.monitoring.coreos.com servicemonitors.monitoring.coreos.com alertmanagers.monitoring.coreos.com prometheusrules.monitoring.coreos.com |
Источник:
https://github.com/helm/charts/tree/master/stable/prometheus-operator
https://coreos.com/operators/prometheus/docs/latest/user-guides/getting-started.html
https://blog.lwolf.org/post/going-open-source-in-monitoring-part-i-deploying-prometheus-and-grafana-to-kubernetes/
https://akomljen.com/get-kubernetes-cluster-metrics-with-prometheus-in-5-minutes/
https://kubernetes.io/blog/2018/07/12/resizing-persistent-volumes-using-kubernetes/
 Опубликовано в рубрике
Опубликовано в рубрике  Метки:
Метки: