 Октябрь 19th, 2019
Октябрь 19th, 2019  Evgeniy Kamenev
Evgeniy Kamenev За основу был взять стек мониторинга отсюда и изменен под свои задачи
https://github.com/stefanprodan/dockprom
Репозитарий с мониторинг стеком досутпен по адресу
https://bitbucket.org/kamaok/monstack/src/master/
Базовая архитектурная схема мониторинг стека имеет вид
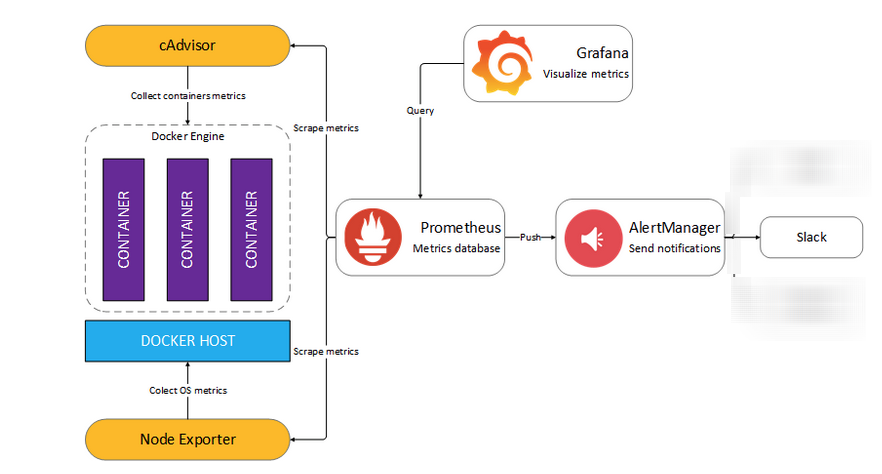
Mониторинг стек состоит из следующих компонентов:
Prometheus(https://https://prometheus.io/) – сбор и хранение метрик
Доступен на URL https://prometehus.mydomain.com
Grafana(https://grafana.org) — визуализация метрик в виде графиков/панелей на dashboard-ах.
Доступна на URL https://grafana.mydomain.com
AlertManger(https://github.com/prometheus/alertmanager) — отправка сообщений в желаемый канал информации (в нашем случае Slack)
Доступен на URL https://alertmanager.mydomain.com
Caddy(https://caddyserver.com) – обратный прокис-сервер с обеспечением Basic-аутентификации для Prometheus, AlertManager, Pushgateway, а также терминирования SSL-соединений для Prometheus, Grafana, AlertManager, Pushgateway
Node-exporter – сборщик метрик c нод/хостов
Cadvisor — сборщик метрик c контейнеров
Для примера, мониторить будем 4 сервера/хоста,
Server{1,2}.mydomain.com — staging сервера
Server{3,4}.mydomain.com — production сервера
Все сервера Bare-metal(или виртуалки)(не облака) с file-based service discovery в качестве механизма обнаружения хостов используемый в Prometheus
Т.е. добавление серверов на мониторинг выполняется вручную путем добавление их в специальные файлы, которые автоматически перечитываются самим Prometheus-ом и он начинает собирать с добавленных серверов и их контейнеров метрики
Иерархия каталогов/файлов имеет следующий вид
|
1 |
# tree |
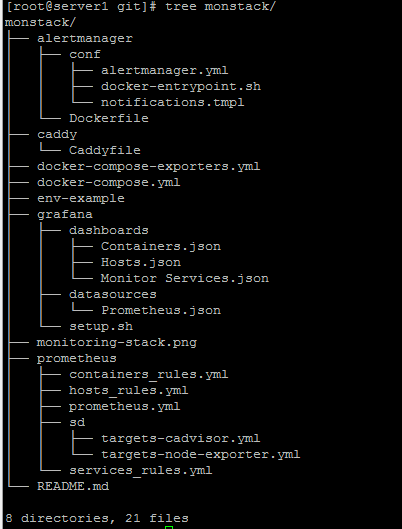
1.Cкопировать файл-шаблон env-example с переменными для docker-compose в .env
(файл, который docker-compose читает при своем запуске) и указать в .env-файле значения для следующих переменных
|
1 |
SLACK_URL |
– это URL для Slack в формате https://hooks.slack.com/services/
|
1 |
SLACK_CHANNEL |
– название канала в Slack
|
1 |
SLACK_USER |
– пользователь, от которого будут приходить сообщения в канал Slack(если не указан, то используется пользователь alertmanager)
|
1 |
ADMIN_PASSWORD |
— пароль пользователя admin, который будет использоваться для аутентификации в Prometheus, Alertmanager, Pushgateway через сервис аутентификации Caddy и для аутентификации в Grafana через встроенную непосредственно в Grafana аутентификацию
|
1 |
DOCKER_REGISTRY_URL |
— это URL приватного Docker-репозитария, из которого/в который будут загружаться наши кастомные/измененные образы
Файл с переменными имеет вид
|
1 |
# nano .env |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
DOCKER_REGISTRY_URL=docker-repo.mydomain.com:5000 ### Prometheus PROMETHEUS_VERSION=2.10.0 PROMETHEUS_MEM_LIMIT=1536m PROMETHEUS_MEM_RESERVATION=1024m ### Alertmanager ALERTMANGER_VERSION=0.17.0 ALERTMANGER_MEM_LIMIT=128m ALERTMANGER_MEM_RESERVATION=64m SLACK_USER=alertmanager SLACK_URL= SLACK_CHANNEL= ### Grafana GRAFANA_VERSION=6.2.5 GRAFANA_MEM_LIMIT=256m GRAFANA_MEM_RESERVATION=128m ADMIN_USER=admin ADMIN_PASSWORD= ### Node-exporter NODE_EXPORTER_VERSION=0.18.1 NODE_EXPORTER_MEM_LIMIT=128m NODE_EXPORTER_MEM_RESERVATION=64m ### Cadvisor CADVISOR_VERSION=0.33.0 CADVISOR_MEM_LIMIT=128m CADVISOR_MEM_RESERVATION=64m ### Pushgateway PUSHGATEWAY_VERSION=0.8.0 PUSHGATEWAY_MEM_LIMIT=128m PUSHGATEWAY_MEM_RESERVATION=64m ### Caddy CADDY_VERSION=latest CADDY_MEM_LIMIT=128m CADDY_MEM_RESERVATION=64m |
2.Собрать и зашрузить в приватный Docker-репозитарий образ для Alertmanager
|
1 |
# cd monstack/alertmanager |
|
1 |
# docker build -t docker-repo.mydomain.com:5000/alertmanager:v0.17.0 . |
|
1 |
# docker push docker-repo.mydomain.com:5000/alertmanager:v0.17.0 |
3.Перетегировать единоразово и загрузить в приватный Docker-репозитарий образ для Caddy
Caddy автоматически получает и автообновляет бесплатные Let’sEncrypt-сертификаты для
Prometheus,grafana,alertmanager,pushgateway. Поэтому для успешного выпуска бесплатных сертификатов от Let’sEncrypt необходимо направить указанные домены {prometheus,grafana,alertmanager,pushgateway}.mydomain.com на IP-адрес сервера, на котором развернут monitoring-стек
Кроме этого Caddy по умолчанию настроен на принудительный редирект с http на https
При первом запуске Caddy попытается получить Let’sEncrypt сертификаты для всех доменов, указанных в кофигурационном файле Caddyfile и для которых не отключено SSL (не указана/не установлен опция tls off)
Больше информации о Caddy доступно из официальной документации
https://caddyserver.com/docs
https://caddyserver.com/docs/automatic-https
Загрузим исходный образ Caddy
|
1 |
# docker pull stefanprodan/caddy |
Перетегируем его на свой образ
|
1 |
# docker tag stefanprodan/caddy docker-repo.mydomain.com:5000/caddy:latest |
Загрузим наш образ в приватный Docker-репозитарий
|
1 |
# docker push docker-repo.mydomain.com:5000/caddy:latest |
Образы для Prometheus, Grafana, Pushgateway, Node-exporter, Cadvisor берем из официальных Docker-репозитариев
В .env файле для docker-compose указаны версии необходимых нам сервисов
После выполнения указанных выше всех трех шагов мониторинг стек готов к своему запуск
Запуск мониторинг стека выполняется командой
|
1 |
# cd monstack && docker-compose up -d |
Docker-compose.yml имеет вид
|
1 |
# nano docker-compose.yml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 |
version: '2.4' networks: monitor-net: driver: bridge volumes: prometheus_data: {} grafana_data: {} alertmanager_data: {} services: prometheus: image: prom/prometheus:v${PROMETHEUS_VERSION} container_name: prometheus volumes: - ./prometheus/:/etc/prometheus/ - prometheus_data:/prometheus command: - '--config.file=/etc/prometheus/prometheus.yml' - '--storage.tsdb.path=/prometheus' - '--web.console.libraries=/etc/prometheus/console_libraries' - '--web.console.templates=/etc/prometheus/consoles' - '--storage.tsdb.retention.time=1500h' - '--web.enable-lifecycle' extra_hosts: - "server1.mydomain.com:10.10.10.1" - "server2.mydomain.com:10.10.10.2" - "server3.mydomain.com:10.10.10.3" - "server4.mydomain.com:10.10.10.4" restart: unless-stopped expose: - 9090 networks: - monitor-net mem_limit: ${PROMETHEUS_MEM_LIMIT} mem_reservation: ${PROMETHEUS_MEM_RESERVATION} labels: org.label-schema.group: "monitoring" alertmanager: image: ${DOCKER_REGISTRY_URL}/alertmanager:v${ALERTMANGER_VERSION} container_name: alertmanager volumes: #- ./alertmanager/conf:/etc/alertmanager/ - alertmanager_data:/alertmanager command: - '--config.file=/etc/alertmanager/alertmanager.yml' - '--storage.path=/alertmanager' environment: - SLACK_URL=${SLACK_URL} - SLACK_CHANNEL=${SLACK_CHANNEL} - SLACK_USER=${SLACK_USER:-alertmanager} restart: unless-stopped expose: - 9093 networks: - monitor-net mem_limit: ${ALERTMANGER_MEM_LIMIT} mem_reservation: ${ALERTMANGER_MEM_RESERVATION} labels: org.label-schema.group: "monitoring" logging: driver: "json-file" options: max-size: "5m" nodeexporter: image: prom/node-exporter:v${NODE_EXPORTER_VERSION} container_name: nodeexporter volumes: - /proc:/host/proc:ro - /sys:/host/sys:ro - /:/rootfs:ro command: - '--path.procfs=/host/proc' - '--path.rootfs=/rootfs' - '--path.sysfs=/host/sys' - '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc)($$|/)' restart: unless-stopped expose: - 9100 networks: - monitor-net mem_limit: ${NODE_EXPORTER_MEM_LIMIT} mem_reservation: ${NODE_EXPORTER_MEM_RESERVATION} labels: org.label-schema.group: "monitoring" logging: driver: "json-file" options: max-size: "5m" cadvisor: image: google/cadvisor:v${CADVISOR_VERSION} container_name: cadvisor volumes: - /:/rootfs:ro - /var/run:/var/run:rw - /sys:/sys:ro - /var/lib/docker/:/var/lib/docker:ro - /cgroup:/cgroup:ro #doesn't work on MacOS only for Linux restart: unless-stopped expose: - 8080 networks: - monitor-net mem_limit: ${CADVISOR_MEM_LIMIT} mem_reservation: ${CADVISOR_MEM_RESERVATION} labels: org.label-schema.group: "monitoring" logging: driver: "json-file" options: max-size: "5m" grafana: image: grafana/grafana:${GRAFANA_VERSION} container_name: grafana volumes: - grafana_data:/var/lib/grafana - ./grafana/datasources:/etc/grafana/datasources - ./grafana/dashboards:/etc/grafana/dashboards - ./grafana/setup.sh:/setup.sh entrypoint: /setup.sh environment: - GF_SECURITY_ADMIN_USER=${ADMIN_USER:-admin} - GF_SECURITY_ADMIN_PASSWORD=${ADMIN_PASSWORD:-admin} - GF_USERS_ALLOW_SIGN_UP=false - GF_METRICS_ENABLED=false restart: unless-stopped expose: - 3000 networks: - monitor-net mem_limit: ${GRAFANA_MEM_LIMIT} mem_reservation: ${GRAFANA_MEM_RESERVATION} labels: org.label-schema.group: "monitoring" logging: driver: "json-file" options: max-size: "5m" pushgateway: image: prom/pushgateway:v${PUSHGATEWAY_VERSION} container_name: pushgateway restart: unless-stopped expose: - 9091 networks: - monitor-net labels: org.label-schema.group: "monitoring" mem_limit: ${PUSHGATEWAY_MEM_LIMIT} mem_reservation: ${PUSHGATEWAY_MEM_RESERVATION} logging: driver: "json-file" options: max-size: "5m" caddy: image: ${DOCKER_REGISTRY_URL}/caddy:${CADDY_VERSION} container_name: caddy ports: - "80:80" - "443:443" volumes: - ./caddy/Caddyfile:/etc/caddy/Caddyfile - ./caddy/.caddy:/root/.caddy:rw environment: - ADMIN_USER=${ADMIN_USER:-admin} - ADMIN_PASSWORD=${ADMIN_PASSWORD:-admin} restart: unless-stopped networks: - monitor-net mem_limit: ${CADDY_MEM_LIMIT} mem_reservation: ${CADDY_MEM_RESERVATION} labels: org.label-schema.group: "monitoring" logging: driver: "json-file" options: max-size: "5m" |
Используется версия docker-compose 2.4, чтобы применялись лимиты на ресурсы(если использовать версию 3, тогда для применения лимитов docker-compose.yml файл необходимо запускать в docker swarm)
Создается сеть типа bridge c именем monitor-net, к которой будут подключены все компоненты мониторинг стека
Для statefull-приложений(Prometheus, Grafana, AlertManager), которые хранят свои данные – создаются docker-тома(volume), которые и используются в соответствующих конфигурационных файлов таких statefull-приложений для хранения на них данных приложений
Для всех контейнеров установлены
— лимиты на резервируемый и максимально используемый размер памяти
— метка(используется для запросов PromQL в Grafana),
— формат и размер лог-файла
— имя сети, к которой необходимо подключить контейнер
— политика автоматического перезапуска контейнера (всегда, за исключением корректной остановки/завершения работы)
— имя контейнера
Более подробное описание каждого сервиса:
Prometheus
Монтирует конфиги с хостового каталога, а также сохраняет свои данные на томе prometheus_data
Время хранения метрик – 1500 часов ~2 месяца (—storage.tsdb.retention.time)
Включена возможность перечитывания конфигурационного файла Prometheus с помощь HTP POST-запроса (—web.enable-lifecycle)
С помощью параметра extra_hosts задаем соответствие имени хоста и его IP-адреса (такое соответствие будет добавлено в файл /etc/hosts внутри контейнера с Prometheus), что позволит Prometheus корректно разименовать хосты и подключиться к ним для сбора метрик
Это необходимо,если, например, доменные имена для целевых хостов не настроены в DNS или имена нстроены в DNS, но разименовываются в IP-адреса, на которых не слушают запросы экспортеры метрик(node-exporter, cadvisor). Такая ситуация, например, возможна, когда доступ к целевым хоста для сбора метрик возможен только по VPN-адресу или по внутренним IP-адресам(на которые в DNS не разименовываются доменные адреса целевых хостов)
Alertmanager
Сохраняет свои данные на томе alertmanager_data
Конфигурационный файл alertmanager.yml уже находится/зашит нами ранее в образ
При старте контейнера выполняется скрипт docker-entrypoint.sh в качестве ENTRYPOINT, в котором динамически подставляются значение параметров
SLACK_URL, SLACK_CHANNEL, SLACK_USER в конфигурационный файл alertmanager.yml
Если необходимо изменить настройки в конфигурационном файле alertmanager.yml, тогда пересобираем образ и пересоздаем контейнер с alertmanager
|
1 |
# cd monstack/alertmanager |
|
1 |
# docker build -t docker-repo.mydomain.com:5000/alertmanager:v0.17.0 . |
|
1 |
# docker push docker-repo.mydomain.com:5000/alertmanager:v0.17.0 |
|
1 |
# cd ../monstack && docker-compose up -d alertmanager |
Либо с помощью одной команды
|
1 |
# ( cd monstack/alertmanager && docker build -t docker-repo.mydomain.com:5000/alertmanager:v0.17.0 . && docker push docker-repo.mydomain.com:5000/alertmanager:v0.17.0 && cd ../ && docker-compose up -d alertmanager) |
После чего проверить наличие сделанных в Alertmanager GUI
https://alertmanager.mydomain.com
Сaddy
Монтирует свой конфигурационный файл Caddyfile с хостового каталога, а также сохраняет свои данные( в том числе выпущенные SSL-сертификаты) в хостовом каталоге
Для аутентификации в Caddy( и соотвественно получения доступа к Prometheus, Alertmanager, Pushgateway, для которых Caddy выступает proxy-сервером) используются значения параметров
ADMIN_USER, ADMIN_PASSWORD, указанных в .env-файле (если не указаны, тога используется admin/admin)
Для Grafana сервиса Caddy выступает в качестве proxy-сервера и не требует базовую аутентификацию при запросах к Grafana т.к. сама Grafana имеет свой внутренний родной механизи аутентификации по логину/паролю
Grafana
Монтирует каталог с источником, откуда брать данные(/grafana/datasources) и каталог своих dashboard-ов (/grafana/dashboards) с хоста
Grafana поддержует динамический provisioning как источников данных/метрик(datasource), так и dashboard-ов
http://docs.grafana.org/administration/provisioning/
Grafana преднастроена для работы с дефолтным истоником данных — Prometheus
|
1 2 3 4 |
* Name: Prometheus * Type: Prometheus * Url: http://prometheus:9090 * Access: proxy |
Сохраняет свои данные на томе grafana_data
Для аутентификации в Grafana используются значения параметров
ADMIN_USER, ADMIN_PASSWORD, указанных в .env-файле (если не указаны, тога используется admin/admin)
Запрещена регистрация новых пользователей(GF_USERS_ALLOW_SIGN_UP=false)
Отключена отдача метрик самой Grafana(GF_METRICS_ENABLED=false)
В комплект включены следующие dashboard-ы
Host Dashboard
Отображает ключевые метрики для мониторинга ресурсов, используемых хостами
|
1 2 3 4 5 6 7 |
* Server uptime, CPU idle percent, number of CPU cores, available memory, swap and storage * System load average graph, running and blocked by IO processes graph, interrupts graph * CPU usage graph by mode (guest, idle, iowait, irq, nice, softirq, steal, system, user) * Memory usage graph by distribution (used, free, buffers, cached) * IO usage graph (read Bps, read Bps and IO time) * Network usage graph by device (inbound Bps, Outbound Bps) * Swap usage and activity graphs |
Containers Dashboard
Отображает ключевые метрики запущенных контейнеров
|
1 2 3 4 5 6 7 8 9 |
* Total containers CPU load, memory usage * Running containers graph, system load graph, IO usage graph * Container CPU usage graph * Container memory usage graph * Container cached memory usage graph * Container Disk I/O Read/Write usage graph * Container Disk IOPS Read/Write usage graph * Container network inbound usage graph * Container network outbound usage graph |
Monitor Services Dashboard
Отображает ключевые метрики для мониторинга контейнеров, которые входят в мониторинг стек
|
1 2 3 4 5 6 7 8 |
* Prometheus container uptime, monitoring stack total memory usage, Prometheus local storage memory chunks and series * Container CPU usage graph * Container memory usage graph * Prometheus chunks to persist and persistence urgency graphs * Prometheus chunks ops and checkpoint duration graphs * Prometheus samples ingested rate, target scrapes and scrape duration graphs * Prometheus HTTP requests graph * Prometheus alerts graph |
Nodeexporter
Запускается для мониторинга хоста, на котором развернут мониторинг стек(т.е. самого себя)
Cadvisor
Запускается для мониторинга контейнеров, запущенных на хосте, на котором развернут мониторинг стек(т.е. мониторинг всех сервисных/служебных контейнеров стека)
Pushgateway
Запускается для приема/получения метрик от хостов/сервисов, которые настроены на отправку таких метрик или от краткосрочных приложений(cron-задач), которые не запущены постоянно и соотвественно Prometheus не может поучать с них метрики
Для отправки метрик такому Pushgateway можно выполнить команду типа
|
1 |
# echo "some_metric 3.14" | curl --data-binary @- https://admin:<admin_password>@pushgateway.mydomain.com/metrics/job/some_job |
Конфигурационный файл Prometheus – prometheus.yml имеет вид
|
1 |
# nano monstack/prometheus/prometheus.yml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
global: scrape_interval: 15s evaluation_interval: 15s # Attach these labels to any time series or alerts when communicating with # external systems (federation, remote storage, Alertmanager). external_labels: monitor: 'prometheus-prod' # Load and evaluate rules in this file every 'evaluation_interval' seconds. rule_files: - "hosts_rules.yml" - "containers_rules.yml" - "services_rules.yml" # A scrape configuration containing exactly one endpoint to scrape. scrape_configs: - job_name: 'prometheus-node-exporter' static_configs: - targets: ['nodeexporter:9100'] - job_name: 'prometheus-cadvisor' static_configs: - targets: ['cadvisor:8080'] - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'prometheus-pushgateway' honor_labels: true static_configs: - targets: ['pushgateway:9091'] - job_name: 'node-exporter' file_sd_configs: - files: - sd/targets-node-exporter.yml - job_name: 'cadvisor' file_sd_configs: - files: - sd/targets-cadvisor.yml alerting: alertmanagers: - scheme: http static_configs: - targets: - 'alertmanager:9093' |
|
1 2 |
Интервал сбора метрик - scrape_interval Интервал проверки - evaluation_interval |
Метка,используемая для определения сервера, с которого было отправлено оповещение в AlertManager
|
1 2 |
external_labels: monitor: 'prometheus-prod' |
Файлы с правилами
|
1 2 3 4 |
rule_files: - "hosts_rules.yml" - "containers_rules.yml" - "services_rules.yml" |
Отправка уведомление в AlertManager при срабатывании правила
|
1 2 3 4 5 6 |
alerting: alertmanagers: - scheme: http static_configs: - targets: - 'alertmanager:9093' |
Снятие метрик/мониторинг prometheus самого себя prometheus-ом
|
1 2 3 |
- job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] |
Снятие меток/мониторинг с Pushgateway
|
1 2 3 4 |
- job_name: 'prometheus-pushgateway' honor_labels: true static_configs: - targets: ['pushgateway:9091'] |
Снятие метрик c Node-exporter-а, который запущен на мониторинг хосте (мониторинг хоста, на котором запущен мониторинг стек)
|
1 2 3 |
- job_name: 'prometheus-node-exporter' static_configs: - targets: ['nodeexporter:9100'] |
Снятие метрик c Cadvisor, который запущен на мониторинг хосте (мониторинг контейнеров, запущенных на мониторинг хосте)
|
1 2 3 |
- job_name: 'prometheus-cadvisor' static_configs: - targets: ['cadvisor:8080'] |
Снятие метрик c Node-exporter-а целевых хостов(мониторинг ресурсов целевых хостов)
|
1 2 3 4 |
- job_name: 'node-exporter' file_sd_configs: - files: - sd/targets-node-exporter.yml |
Снятие метрик c Cadvisor целевых хостов(мониторинг запущенных контейнеров на целевых хостах)
|
1 2 3 4 |
- job_name: 'cadvisor' file_sd_configs: - files: - sd/targets-cadvisor.yml |
При добавлении хостов в файлы sd/targets-node-exporter.yml/ и/или sd/targets-cadvisor.yml Prometheus автоматически их перечитывает и начинает собирать метрики с указанных хостов/контейнеров
Для добавления целевого хоста и запущенных на нем контейнеров на мониторинг необходимо:
1.Установить Node-exporter и Cadvisor на целевом хосте и проверить доступность метрик с мониторинг хоста до Node-exporter и Cadvisor
|
1 |
# curl <IP-address-target-host/domain_name>:9100/metrics |
|
1 |
# curl <IP-address-target-host/domain_name>:8888/metrics |
2. Добавить в опцию extra-hosts в service prometheus в docker-compose.yml файле соотвествие имени хоста и его IP-адреса
|
1 |
# nano docker-compose.yml |
|
1 2 3 4 5 6 7 8 9 |
… services: prometheus: …… extra_hosts: - "server5.mydomain.com:10.10.10.5" - "server6.mydomain.com:10.10.10.6" …… |
3.Пересобрать Prometheus контейнер и проверить налиичие добавленных строк в файле /etc/hosts внутри Prometheus-экспортера
|
1 |
# cd ~/monstack && docker-compose up -d prometheus |
|
1 |
# dce prometheus cat /etc/hosts |
4.Добавить в Prometheus сбор метрик с Node-exporter/Cadvisor с целевого хоста
|
1 |
# nano prometheus/sd/targets-node-exporter.yml |
|
1 2 3 4 5 6 7 8 9 10 11 |
--- - targets: - server5.mydomain.com:9100 labels: env: staging job: node-exporter - targets: - server6.mydomain.com:9100 labels: env: prod job: node-exporter |
|
1 |
# nano prometheus/sd/targets-cadvisor.yml |
|
1 2 3 4 5 6 7 8 9 10 11 |
--- - targets: - server5.mydomain.com:8888 labels: env: staging job: cadvisor - targets: - server6.mydomain.com:8888 labels: env: prod job: cadvisor |
5.Проверить наличие добавленных целей для Node-exporter и Cadvisor в Prometheus GUI
https://prometheus.mydomain.com/targets
Правила Prometheus
Для мониторинг ресурсов хостов использую следующие правила
|
1 |
# nano prometheus/hosts_rules.yml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 |
groups: - name: hosts rules: ########## Load Average ########## - alert: high_cpu_load_average expr: ((node_load1) / count without (cpu,mode) (node_cpu_seconds_total{mode="system"}) ) > 0.8 for: 3m labels: severity: warning annotations: summary: "Warning: High CPU Load average(>0.8) on the host {{ $labels.instance }}" description: "Host CPU load average is {{ $value}} on the host {{ $labels.instance }}" ########## CPU ########## - alert: high_cpu_load_average expr: ((node_load1) / count without (cpu,mode) (node_cpu_seconds_total{mode="system"}) ) > 1 for: 3m labels: severity: critical annotations: summary: "Critical: High CPU Load average(>1) on the host {{ $labels.instance }}" description: "Host CPU load average is {{ $value}} on the host {{ $labels.instance }}" - alert: high_cpu_usage expr: 100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80 for: 3m labels: severity: warning annotations: summary: "Warning: High CPU usage(>80%) on the host {{ $labels.instance }}" description: "Host CPU usage is {{ humanize $value}}% on the host {{ $labels.instance }}" - alert: high_cpu_usage expr: 100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 100 for: 3m labels: severity: critical annotations: summary: "Critical: High CPU usage(>100%) on the host {{ $labels.instance }}" description: "Host CPU usage is {{ humanize $value}}% on the host {{ $labels.instance }}" #- alert: high_cpu_context_switching_non_prod.mydomain.com # expr: rate(node_context_switches_total{instance!~"server1.mydomain.com.+|server2.mydomain.com.+"}[5m]) > 6000 # for: 5m # labels: # severity: warning # annotations: # summary: "Warning: High CPU context switching(>6000) on the host {{ $labels.instance }}" # description: "Host cpu context switching is {{ humanize $value}}" #- alert: high_cpu_context_switching_prod.mydomain.com # expr: rate(node_context_switches_total{instance=~"server3.mydomain.com.+|server4.mydomain.com.+"}[5m]) > 45000 # for: 5m # labels: # severity: warning # annotations: # summary: "Warning: High CPU context switching(>45000) on the host {{ $labels.instance }}" # description: "Host cpu context switching is {{ humanize $value}}" ########## Memory ########## - alert: high_memory_usage expr: ((node_memory_MemTotal_bytes{instance!~"server3.mydomain.com.+",instance!~"server4.mydomain.com.+"} - node_memory_MemAvailable_bytes{instance!~"server3.mydomain.com.+",instance!~"server4.mydomain.com.+"}) / node_memory_MemTotal_bytes{instance!~"server3.mydomain.com.+",instance!~"server4.mydomain.com.+"}) * 100 > 80 for: 3m labels: severity: warning annotations: summary: "Warning: High memory usage(>80%) on the host {{ $labels.instance }}" description: "Host memory usage is {{ humanize $value}}% on the host {{ $labels.instance }}" - alert: high_memory_usage expr: ((node_memory_MemTotal_bytes{instance!~"server3.mydomain.com.+",instance!~"server4.mydomain.com.+"} - node_memory_MemAvailable_bytes{instance!~"server3.mydomain.com.+",instance!~"server4.mydomain.com.+"}) / node_memory_MemTotal_bytes{instance!~"server3.mydomain.com.+",instance!~"server4.mydomain.com.+"}) * 100 > 90 for: 3m labels: severity: critical annotations: summary: "Critical: High memory usage(>90%) on the host {{ $labels.instance }}" description: "Host memory usage is {{ humanize $value}}% on the host {{ $labels.instance }}" - alert: high_memory_usage_server{3,4} expr: ((node_memory_MemTotal_bytes{instance=~"server3.mydomain.com.+|server4.mydomain.com.+"} - node_memory_MemAvailable_bytes{instance=~"server3.mydomain.com.+|server4.mydomain.com.+"}) / node_memory_MemTotal_bytes{instance=~"server3.mydomain.com.+|server4.mydomain.com.+"}) * 100 > 85 for: 3m labels: severity: warning annotations: summary: "Warning: High memory usage(>85%) on the host {{ $labels.instance }}" description: "Host memory usage is {{ humanize $value}}% on the host {{ $labels.instance }}" - alert: high_memory_usage_server_{3,4} expr: ((node_memory_MemTotal_bytes{instance=~"server3.mydomain.com.+|server4.mydomain.com.+"} - node_memory_MemAvailable_bytes{instance=~"server3.+mydomain.com.+|server4.mydomain.com.+"}) / node_memory_MemTotal_bytes{instance=~"server3.mydomain.com.+|server4.mydomain.com.+"}) * 100 > 95 for: 3m labels: severity: critical annotations: summary: "Critical: High memory usage(>95%) on the host {{ $labels.instance }}" description: "Host memory usage is {{ humanize $value}}% on the host {{ $labels.instance }}" ########## Swap ########## - alert: high_swap_usage expr: (1 - (node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes)) * 100 > 60 for: 3m labels: severity: warning annotations: summary: "Warning: High swap usage(>60%) on the host {{ $labels.instance }}" description: "Host swap usage is {{ humanize $value}}%" - alert: high_swap_usage expr: (1 - (node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes)) * 100 > 80 for: 3m labels: severity: critical annotations: summary: "Critical: High swap usage(>80%) on the host {{ $labels.instance }}" description: "Host swap usage is {{ humanize $value}}%" ########## Disk ########## - alert: high_ROOT/BOOT_inode_disk_usage expr: 100 - ((node_filesystem_files_free{mountpoint =~"/|/boot",fstype=~"xfs|ext4"} / node_filesystem_files{mountpoint=~"/|/boot",fstype=~"xfs|ext4"}) *100) > 80 for: 1m labels: severity: warning annotations: summary: "Warning: Disk {{ $labels.mountpoint }} inode usage is almost full(>80%) on the host {{ $labels.instance }}" description: "Host disk {{ $labels.mountpoint }} inode usage is {{ humanize $value}}%" - alert: high_ROOT/BOOT_inode_disk_usage expr: 100 - (node_filesystem_files_free{mountpoint =~"/|/boot",fstype=~"xfs|ext4"} / node_filesystem_files{mountpoint=~"/|/boot",fstype=~"xfs|ext4"})*100 > 90 for: 1m labels: severity: critical annotations: summary: "Critical: Disk {{ $labels.mountpoint }} inode usage is almost full(>90%) on the host {{ $labels.instance }}" description: "Host disk {{ $labels.mountpoint }} inode usage is {{ humanize $value}}%" - alert: high_ROOT/BOOT_storage_disk_usage expr: 100 - (node_filesystem_free_bytes{mountpoint=~"/|/boot",fstype=~"xfs|ext4"} / node_filesystem_size_bytes{mountpoint=~"/|/boot",fstype=~"xfs|ext4"} )*100 > 80 for: 1m labels: severity: warning annotations: summary: "Warning: Disk {{ $labels.mountpoint }} storage is almost full(>80%) on the host {{ $labels.instance }}" description: "Host disk {{ $labels.mountpoint }} storage usage is {{ humanize $value}}%" - alert: high_ROOT/BOOT_storage_disk_usage expr: 100 - (node_filesystem_free_bytes{mountpoint=~"/|/boot",fstype=~"xfs|ext4"} / node_filesystem_size_bytes{mountpoint=~"/|/boot",fstype=~"xfs|ext4"} )*100 > 90 for: 1m labels: severity: critical annotations: summary: "Critical: Disk {{ $labels.mountpoint }} storage is almost full(>90%) on the host {{ $labels.instance }}" description: "Host disk {{ $labels.mountpoint }} storage usage is {{ humanize $value}}%" - alert: node_disk_fill_rate_6h expr: predict_linear(node_filesystem_free_bytes{mountpoint=~"/|/boot"}[1h], 6 * 3600) < 0 for: 1h labels: severity: critical annotations: summary: "Critical: Disk {{ $labels.mountpoint }} is going to fill up in 6h on the host {{ $labels.instance }}" description: "Host disk {{ $labels.mountpoint }} is going to fill up on the host {{ $labels.instance }}" - alert: high_disk_read_latency expr: rate(node_disk_read_time_seconds_total{device!~"md[0-9]"}[1m]) / rate(node_disk_reads_completed_total{device!~"md[0-9]"}[1m]) > 100 for: 1m labels: severity: warning annotations: summary: "Warning: High disk read latency(>100ms) on the host {{ $labels.instance }}" description: "Host disk read latency is {{ humanize $value}}ms" - alert: high_disk_write_latency expr: rate(node_disk_write_time_seconds_total{device!~"md[0-9]"}[1m]) / rate(node_disk_writes_completed_total{device!~"md[0-9]"}[1m]) > 100 for: 1m labels: severity: warning annotations: summary: "Warning: High disk write latency(>100ms) on the host {{ $labels.instance }}" description: "Host disk write latency is {{ humanize $value}}ms" - alert: high_disk_input_output_latency expr: (irate(node_disk_io_time_seconds_total{device!~"md[0-9]|nvme[0-9].+"}[5m])) * 1000 > 1000 for: 5m labels: severity: warning annotations: summary: "Warning: High disk input/output latency(>1000ms) on the host {{ $labels.instance }}" description: "Host disk input/output latency is {{ humanize $value}}ms" - alert: high_disk_read_rate expr: sum by (instance,device) (rate(node_disk_read_bytes_total{device!~"md[0-9]"}[2m]) /1024/1024) > 30 for: 5m labels: severity: warning annotations: summary: "Warning: High disk read rate(>30MB/s) on the host {{ $labels.instance }} on the disk {{ $labels.device }} for more than 5 minutes" description: "Host disk read rate is {{ humanize $value}}MB/s" - alert: high_disk_write_rate expr: sum by (instance,device) (rate(node_disk_written_bytes_total{device!~"md[0-9]"}[2m]) /1024/1024) > 30 for: 5m labels: severity: warning annotations: summary: "Warning: High disk write rate(>30MB/s) on the host {{ $labels.instance }} on the disk {{ $labels.device }} for more than 5 minutes" description: "Host disk write rate is {{ humanize $value}}MB/s" - alert: software_raid_is_broken expr: (node_md_disks_active / node_md_disks) != 1 for: 1m labels: severity: critical annotations: summary: "Critical: Software raid is broken for device {{ $labels.device }} on the host {{ $labels.instance }} " description: "Software raid is broken on the host {{ $labels.instance }}" - alert: software_raid_is_not_active expr: node_md_is_active != 1 for: 1m labels: severity: critical annotations: summary: "Critical: Software raid is not active for device {{ $labels.device }} on the host {{ $labels.instance }} " description: "Software raid is not active on the host {{ $labels.instance }}" ########## Network ########## - alert: high_network_input_throughput expr: sum by (instance) (rate(node_network_receive_bytes_total{instance!~"server3.+",instance!~"server4.+"}[2m])) / 1024 / 1024 > 50 for: 3m labels: severity: warning annotations: summary: "Warning: High network input throughput(>50MB/s) on the host {{ $labels.instance }}" description: "Host network input throughput is {{ humanize $value}}MB/s" - alert: high_network_input_throughput_server{3_4}.mydomain.com expr: sum by (instance) (rate(node_network_receive_bytes_total{instance=~"server3.+|server4.+"}[2m])) / 1024 / 1024 > 70 for: 3m labels: severity: warning annotations: summary: "Warning: High network input throughput(>70MB/s) on the host {{ $labels.instance }}" description: "Host network input throughput is {{ humanize $value}}MB/s" - alert: high_network_output_throughput expr: sum by (instance) (rate(node_network_transmit_bytes_total{instance!~"server1.+",instance!~"server2.+"}[2m])) / 1024 / 1024 > 50 for: 3m labels: severity: warning annotations: summary: "Warning: High network output throughput(>50MB/s) on the host {{ $labels.instance }}" description: "Host network output throughput is {{ humanize $value}}MB/s" - alert: high_network_output_throughput_server{3_4}.mydomain.com expr: sum by (instance) (rate(node_network_transmit_bytes_total{instance=~"server3.+|server4.+"}[2m])) / 1024 / 1024 > 70 for: 3m labels: severity: warning annotations: summary: "Warning: High network output throughput(>70MB/s) on the host {{ $labels.instance }}" description: "Host network output throughput is {{ humanize $value}}MB/s" ########## Instance(exporter) ########## - alert: instance_down expr: up == 0 for: 3m labels: severity: critical annotations: description: "Instance {{ $labels.instance }} of job {{ $labels.job }} has been down for more than 3 minutes." summary: "Instance {{ $labels.instance }} is down" |
Для мониторинг ресурсов контейнеров использую следующие правила
Мониторим только наличие необходимых запущенных контейнеров
Правила для метрик контейнеров не настраивал
|
1 |
# nano prometheus/containers_rules.yml |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
groups: - name: containers rules: - alert: Some container is down on the host server1 expr: absent (container_start_time_seconds{image!="",instance="server1.mydomain.com:8888",name=~".+mysql.+"} ) for: 1m labels: severity: critical annotations: summary: "Critical: Some container is down on the host {{ $labels.instance }} for more than 1 minutes" description: "Some container is down on the host {{ $labels.instance }}" - alert: Some container is down on the host server2 expr: absent (container_start_time_seconds{image!="",instance="server2.mydomain.com:8888",name=~".+redis.+"} ) or absent (container_start_time_seconds{image!="",instance="server2.mydomain.com:8888",name=~".+nginx.+"} ) for: 1m labels: severity: critical annotations: summary: "Critical: Some container is down on the host {{ $labels.instance }} for more than 1 minutes" description: "Some container is down on the host {{ $labels.instance }}" - alert: Some container is down on the host server3 expr: absent (container_start_time_seconds{image!="",instance="server3.mydomain.com:8888",name=~".+nginx.+"} ) or absent (container_start_time_seconds{image!="",instance="server3.mydomain.com:8888",name=~".+php-fpm.+"} ) or absent (container_start_time_seconds{image!="",instance="server3.mydomain.com:8888",name=~".+redis.+"} ) or absent (container_start_time_seconds{image!="",instance="server3.mydomain.com:8888",name=~".+varnish.+"} ) or absent (container_start_time_seconds{image!="",instance="server3.mydomain.com:8888",name=~".+mysql.+"} ) for: 1m labels: severity: critical annotations: summary: "Critical: Some container is down on the host {{ $labels.instance }} for more than 1 minutes" description: "Some container is down on the host {{ $labels.instance }}" - alert: Some container is down on the host server4 expr: absent (container_start_time_seconds{image!="",instance="server4:8888",name=~".+beanstalkd.+"} ) or absent (container_start_time_seconds{image!="",instance="server4:8888",name=~".+nginx.+"} ) or absent (container_start_time_seconds{image!="",instance="server4:8888",name=~".+php-fpm.+"} ) or absent (container_start_time_seconds{image!="",instance="server4:8888",name=~".+php-worker.+"} ) or absent (container_start_time_seconds{image!="",instance="server4:8888",name=~".+redis.+"} ) or absent (container_start_time_seconds{image!="",instance="server4:8888",name=~".+mysql.+"} ) for: 1m labels: severity: critical annotations: summary: "Critical: Some container is down on the host {{ $labels.instance }} for more than 1 minutes" description: "Some container is down on the host {{ $labels.instance }}" |
Изменение/добавление/удаление правил Prometheus
1.Изменение/добавление/удаление правила в файле/файлах prometheus/containers_rules.yml/ prometheus/containers_rules.yml
2.Прверка синтаксиса основного конфигурационного файла prometheus и всех подключаемых файлов с правилами
|
1 |
# (cd ./monstack && ../prometheus-2.10.0.linux-amd64/promtool check config ./prometheus/prometheus.yml && echo OK || echo FAIL) |
Как получить утилиту promtool указано в этой статье
https://kamaok.org.ua/?p=3090
3.Перезагрузка основного конфигурационного файла Prometheus путем отправки HTTP POST-запроса
|
1 |
# curl -X POST https://admin:<admin_password>@prometheus.mydomain.com/-/reload |
4.Проверка наличия изменений в правилах через Prometheus GUI
https://prometheus.mydomain.com/alerts
Мониторинг различных приложений настраивается в файле и такая настройка изложена в отдельных статьях
Мониторинг Nginx в Prometheus
Мониторинг PHP-FPM в Prometheus
Мониторинг Redis в Prometheus
Мониторинг MySQL в Prometheus
Мониторинг Beanstalkd в Prometheus
Мониторинг Varnish
Мониторинг доступности сайта в Prometheus
Мониторинг ICMP-доступности хоста в Prometheus
Мониторинг доступности порта хоста в Prometheus
Источник:
https://github.com/stefanprodan/dockprom
https://prometheus.io/docs/prometheus/latest/getting_started
 Опубликовано в рубрике
Опубликовано в рубрике  Метки:
Метки: