 Февраль 28th, 2020
Февраль 28th, 2020  Evgeniy Kamenev
Evgeniy Kamenev Статья состоит из трех частей:
1.Настройка Elasticsearch+Fluentd+Curator+Cerebro на коллекторе(сервере) – Часть-1
2.Настройка Fluentd-агента на целевом хосте(клиенте), с которого нужно собирать логи – Часть-2
3.Настройка Filebeat-агента на целевом хосте(клиенте), с которого нужно собирать логи – Часть-3
Это Часть-1 статьи
За основу был взять стек мониторинга отсюда и изменен под свои задачи
https://medium.com/genesis-media/efk-elasticsearch-fluentd-kibana
Репозитарий с мониторинг стеком доступен по адресу
https://bitbucket.org/kamaok/logstack/src/master/
Базовая архитектурная схема мониторинг стека имеет вид:

Алгоритм действий состоит из следующих шагов:
1.Базовое описание стека
2.Установка и настройка Elasticsearch+Kibana-коллектора(серверной части)
3.Настройка аутентификации и авторизации в Elasticsearch/Kibana
4.Установка и настройка Cerebro и Curator-сервисов
5.Создание пользователя fluentd с необходимыми привиллегиями в Elastcisearch, который будет использоваться в Fluentd/Filebeat-агентах для аутентификации/авторизации в Elasticsearch
6.Установка и настройка на целевом хосте Fluentd-агента, с помощью которого собираем логи(все логии, кроме mysql-логов)
7.Установка и настройка на целевом хосте Filebeat-агента, с помощью которого собираем только MySQL error/slow-логи
8.Создание и сохранение Search, Vizualization, Dashboard в Kibana
1.Базовое описание стека
Mониторинг стек состоит из следующих компонентов:
Elasticsearch— хранение, индексация, поиск логов
Fluentd – сбор, фильтрация, парсинг логов, их буферизация и отправка на Elasticsearch
Kibana – визуализация логов/данных через выполнения API-запросов к Elasticsearch
Cerebro – просмотр и упралвение Elasticsearch индексами, шаблонами, нодами
Curator – работа с Elasticsearch-индексами( удаление индексов старше определенного количества времени, в нашем случае больше 14 дней)
Caddy – Обратный прокси-сервер для Kibana
Elasticsearch, Kibana, Caddy, Cerebo, Curator, запущены на одном сервере (физическом или виртуальном, не важно) через docker-compose
SSL-терминирование происходит на Cloudflare и чистый http направляется на Caddy-сервис, который выступает в качестве proxy-сервера к Kibana
Вместо Caddy можно использовать Nginx, на котором настроить базовую аутентификацию для доступа к Kibana, такой Nginx будет выступать в качестве прокси-сервера к Кибана.
Также на этом Nginx сервере можно настроить SSL-терминирование(если не используется сторонний сервис по SSL-терминированию)
Доступ к Elasticsearch ограничен по сети с помощью OpenVPN-туннеля(т.е. Elasticsearch доступен снаружи только через Openvpn-туннельный адрес), несмотря на то, что также будет включена базовая аутентификация и авторизация в Elasticsearch
Если нет возможности/желания ограничивать доступ на уровне туннелей, тогда альтернативным вариантом могут быть
А) базовая аутентификация + SSL на Elasticsearch
Б) ограничение доступа к порту Elastisearch на уровне файрволла iptables(правила добавляем в цепочку DOCKER-USER)
Например:
|
1 |
# iptables -I DOCKER-USER -s target-host/32 -p tcp -m tcp --dport 9200 -j ACCEPT |
|
1 |
# iptables -I DOCKER-USER 2 -p tcp -m tcp --dport 9200 -j DROP |
Реализован сбор следующих логов:
1. Docker nginx access/error-logs
2. Docker PHP-FPM logs
3. System logs (/var/log/messages – Centos, /var/log/syslog – Ubuntu/Debian)
4. Secure logs (/var/log/secure – Centos, /var/log/auth.log – Ubuntu/Debian)
5. Bash history (/var/log/bash_history) – все выполненные консольные команды на серверах
6. MySQL error/slow logs
Nginx access лог и php-fpm логи собираем с Docker-контейнеров Nginx и PHP-FPM
Nginx error-логи Docker-контейнеров собираем из log-файла, который монтируется с хоста в контейнер
System и Security логи собираем из соответствующих лог файлов на хосте
Все выполненные на целевых хостах команды собираются/дублируются в файл /var/log/bash_history, с которого и собираются bash-history-логи
MySQL логи ошибок и медленных запросов собираются с помощью filebeat(чтобы просто посмотреть альтернативу fluentd)
Сбором логов на целевых хостах занимается Fluentd-агент(для всех вышеуказанных логов, за исключением логов MySQL, сбор которых я преднамеренно оставил за Filebeat-агентом, чтобы рассмотреть его как альтернативу Fluentd-агенту)
Fluentd собирает, фильтрует(отбрасывая ненужные для нас логи контейнеров), парсит, буферизирует логи и порциями отправляет в Elasticsearch
Запущенные контейнеры и прослушиваемые порты на интерфейсах имеют вид
|
1 |
# docker-compose ps |
|
1 2 3 4 5 6 7 |
Name Command State Ports ---------------------------------------------------------------------------------------------------------------------- caddy /sbin/tini -- caddy -agree ... Up 0.0.0.0:80->80/tcp cerebro /docker-entrypoint.sh /opt ... Up 127.0.0.1:9000->9000/tcp curator /docker-entrypoint.sh cron ... Up elasticsearch /usr/local/bin/docker-entr ... Up 10.10.111.1:9200->9200/tcp,127.0.0.1:9200->9200/tcp, 9300/tcp kibana /usr/local/bin/kibana-docker Up 127.0.0.1:5601->5601/tcp |
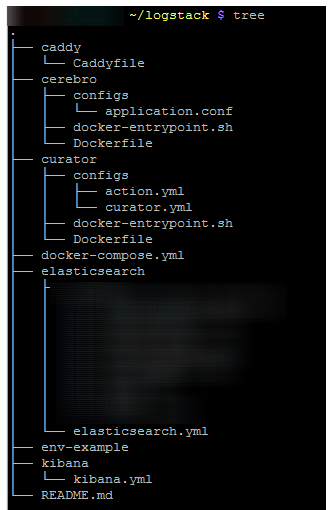
Иерархия каталогов/файлов имеет следующий вид
|
1 |
# tree |
2. Установка и настройка Elastcisearch+Kibana-коллектора(серверной части)
Перед запуском логгинг стека необходимо выполнить первоначальную его настройку
1.Копирование файл-шаблона env-example с переменными для docker-compose в .env
(файл, который docker-compose читает при своем запуске) и указать в .env-файле значения для следующей переменной
|
1 |
KIBANA_SERVER_NAME |
– URL, на котором доступна Kibana (например, kibana.mydomain.com)
2.Создание и запуск пока ТОЛЬКО Elasticsearch и Caddy-контейнеров
При необходимости измените значение переменной
|
1 |
ELASTICSEARCH_JVM_HEAP |
Если необходимо отключить аутентификацию/авторизацию в Elasticsearch/Kibana, тогда измените значение опции
|
1 |
xpack.security.enabled |
на false
Кстати, по умолчанию для free base лицензии она выключена
Сравнение лицензий Elastic Stack доступно по ссылке
https://www.elastic.co/subscriptions
Также измените строку, указав в ней IP-адрес, на который будут подключаться клиенты(fluentd-агенты)
|
1 |
- "10.10.111.1:9200:9200" |
|
1 |
# docker-compose up -d --no-deps elasticsearch caddy |
Проверяем,что требуется аутентификация для доступа в Elasticsearch
|
1 |
# curl http://127.0.0.1:9200 |
Данные(индексы, служебные данные), логи и конфигурационный файл Elasticsearch монтируется с хоста в docker-контейнер
Конфигурационный файла elasticsearch.yml имеет вид:
|
1 2 3 4 5 |
cluster.name: "docker-cluster" network.host: 0.0.0.0 xpack.security.enabled: true bootstrap.memory_lock: true xpack.monitoring.enabled: true |
|
1 |
cluster.name: |
— произвольное имя
|
1 |
network.host: 0.0.0.0 |
— интерфейс, на котором elastcisearch будет слушать запросы внутри docker-контейнера( а уже через опцию ports в docker-compose.yml файле мы выбрасываем Elasticsearch наружу на нужный нам интерфейс)
|
1 |
xpack.security.enabled: true |
– включение аутентификации/авторизации в Elasticsearch/Kibana
|
1 |
bootstrap.memory_lock: true |
– указать для Elasticsearch сразу откусывать/забирать весь размер выделяемой для него оперативной памяти( в нашем случае 4GB)
|
1 |
xpack.monitoring.enabled: true |
— включение мониторинга Elastcisearch и Kibana
Это позволяет смотреть утилизацию ресурсов, время выполнения запросов к Elasticsearch и другую полезную информацию по ElasticSearch и Kibana
Кроме включения поддержки мониторинга Elasticsearch/Kibana на уровне указанной выше настройки необходимо также произвести непосредственную активацию мониторинга в WEB-интерфейсе Kibana
|
1 |
Kibana->Stack Monitoring |
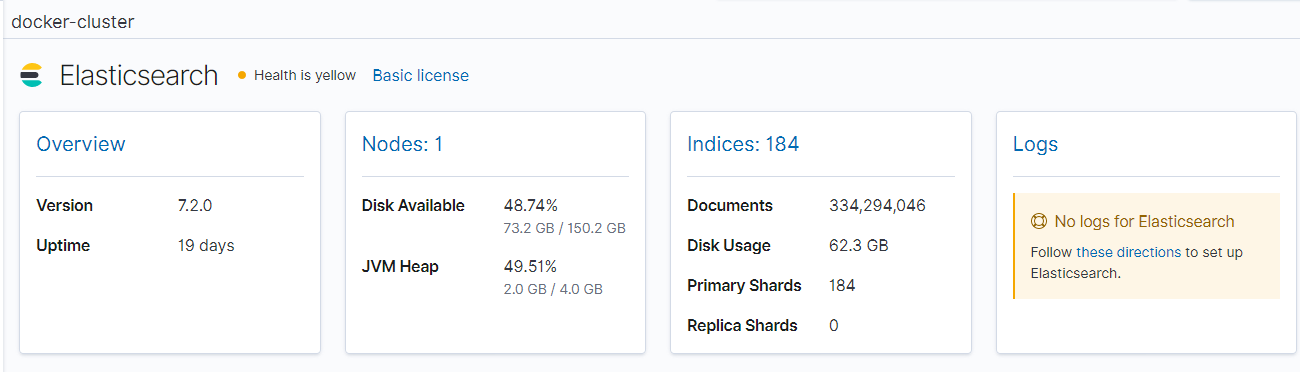
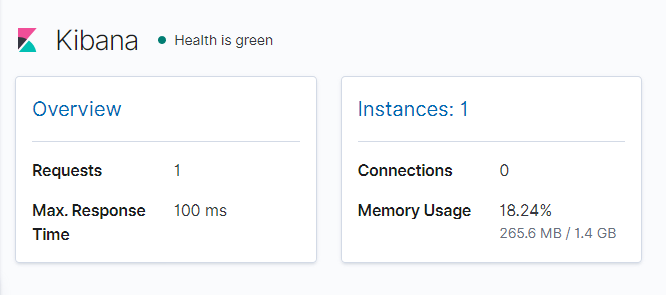
В результе появляется страница с базовой информацией о Elasticsearch и Kibana инстансах
Т.к. нода/инстанс с Elasticsearch один и нет кластера, поэтому по умолчанию его статус желтый, а не зеленый.
Более детальная информация о Elasticsearch/Kibana доступны при нажатии на вкладках
|
1 |
Overview/Instances/Nodes/Indices |
Статистика по Elasticsearch/Kibana хранится в служебных индексах с именами
|
1 2 |
.monitoring-es-7-год.месяц.день .monitoring-kibana-7-год.месяц.день |
Для удаления старых индексов можно использовать либо сервис curator либо настроить Index lifecycle policy
Например, в Index Lifecycle Policy (Kibana->Management->Index Lifecycle Policy) создается политика по удалению индексов старше 7 дней:
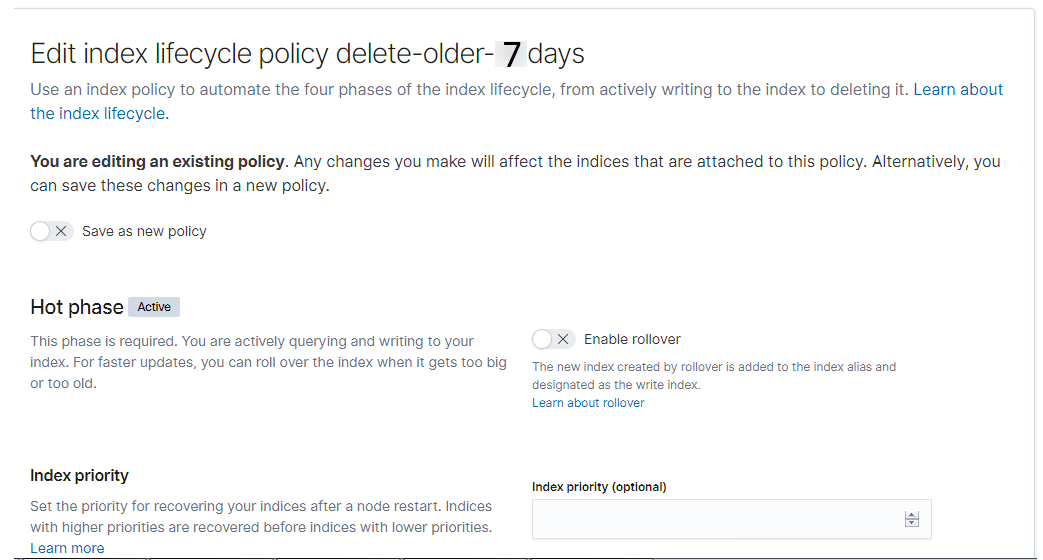
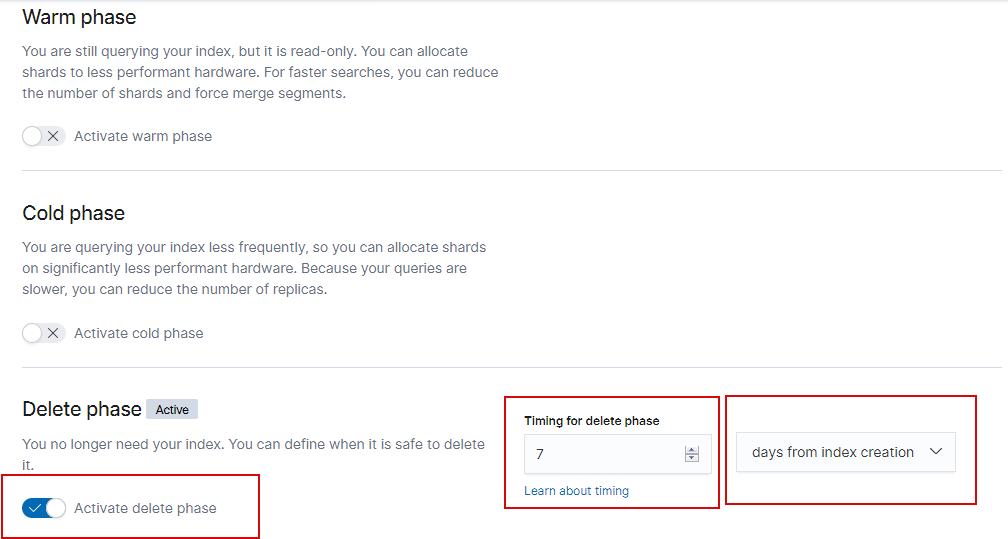
После чего необходимо назначить это политику на индексные шаблоны
|
1 2 |
Kibana->Management->Index Lifecycle Policy->Policy name->Actions->Add policy to index template-> Select Index template-> |
|
1 2 |
- .monitoring-es - .monitoring-kibana |
Таким образом указанные выше служебные индексы по мониторингу Elasticsearch/Kibana старше 7 дней будут автоматически удаляться.
Конфигурационный файл Kibana kibana.yml имеет вид:
|
1 2 3 4 |
server.host: "0" elasticsearch.hosts: [ "http://elasticsearch:9200" ] xpack.monitoring.ui.container.elasticsearch.enabled: true csp.strict: true |
|
1 |
server.host: "0" |
— на каком интерфейсе внутри docker-контейнера будет слушать запросы Kibana( в данном случае это аналогично 0.0.0.0 — всем интерфейсам(однако наружу на хост будет выброшен только 127.0.0.1 интерфейс для Kibana(например, можно использовать его через ssh-туннель напрямую подключаясь к Kibana, не используя Caddy-сервис)
|
1 |
elasticsearch.hosts: - ["http://elasticsearch:9200"] |
– URL, по которому доступен Elastcisearch
|
1 |
xpack.monitoring.ui.container.elasticsearch.enabled: true |
– включение Cgroup-based мониторинга для Elastcisearch, запущенного в контейнере
https://www.elastic.co/guide/en/kibana/7.2/monitoring-settings-kb.html
|
1 |
csp.strict: true |
– включение Content Security Policy в Kibana(заблокирует доступ к Kibana с любого браузера, который не обеспечивает даже элементарный набор защит CSP)
https://www.elastic.co/guide/en/kibana/7.2/production.html
3.Настройка аутентификации и авторизации в Elasticsearch/Kibana
1.Генерирование паролей для дефолтных (уже существующих в поставке) пользователей
|
1 |
# docker-compose exec elasticsearch bash |
|
1 |
[root@db313cef264d elasticsearch]# bin/elasticsearch-setup-passwords auto |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Changed password for user elastic PASSWORD elastic = elasticsearchpassword Changed password for user kibana PASSWORD kibana = kibanapassword Changed password for user apm_system PASSWORD apm_system = password1 Changed password for user logstash_system PASSWORD logstash_system = password2 Changed password for user beats_system PASSWORD beats_system = password3 Changed password for user remote_monitoring_user PASSWORD remote_monitoring_user = password4 |
Elasticsearch становится доступным с логином/паролем
|
1 2 3 |
http://127.0.0.1:9200/ Login: elastic Password: elasticsearchpassword |
Проверка успешной аутентификации
|
1 |
# curl -u elastic:elasticsearchpassword http://127.0.0.1:9200/ |
|
1 |
# curl -u elastic:elasticsearchpassword http://127.0.0.1:9200/_xpack/security/_authenticate?pretty |
2.Настройка Kibana для аутентификации в Elasticsearch
Заполняем переменные для аутентификации/авторизации в Elasticsearch в .env-файле
|
1 |
# nano .env |
|
1 2 |
KIBANA_ELASTICSEARCH_USERNAME=kibana KIBANA_ELASTICSEARCH_PASSWORD=kibanapassword |
3.Создание и запуск Kibana контейнера
|
1 |
# docker-compose up -d --no-deps kibana |
|
1 |
# docker-compose logs kibana |
Заходим в Web-интрефейс Kibana под пользователем elastic и с паролем, сгенерированным ранее(в нашем случае с паролем elasticsearchpassword)
|
1 2 3 |
http://${KIBANA_SERVER_NAME} Login: elastic Password: elasticsearchpassword |
После чего в Kibana->Management появляется меню Security, в котором есть возможность добавлять пользователей и роли
На данном этапе мы создали и запустили следующие контейнеры/сервисы
Elasticsearch, Kibana, Caddy
4.Установка и настройка Cerebro и Curator-сервисов
Для запуска контейнеров Curator и Cerebro нам необходимо создать отдельного пользователя, который будет использоваться этими службами для аутентификации и авторизации в ElasticSearch
Создание служебного пользователя (например, с именем myuser) и назначение ему дефолтной роль superuser
Роль superuser – это существующая в заводской поставке роль с макcимально полными правами
Т.к. эти контейнеры(Cerebro, Curator) запускаются локально, то с точки зрения безопасности приемлемо дать полный доступ для этого пользователя myuser путем назначение ему роли superuser
|
1 |
Kibana->Management->Security->Users->Create user |
После чего добавляем этого служебного пользователя и пароль в соответствующие переменные в .env-файле
|
1 2 3 4 |
CURATOR_USERNAME=myuser CURATOR_PASSWORD=myuserpassword CEREBRO_USERNAME myuser CEREBRO_PASSWORD=myuserpassword |
Создание и запуск Cerebro и Curator контейнеров
|
1 |
# docker-compose up -d --no-deps cerebro curator |
Рассмотрим конфигурацию сервиса Curator
В основном конфигурационном файле curator.yml
указываем подключение к elastcisearch
|
1 2 |
hosts: - elasticsearch |
При создании контейнера будет выполнен скрипт docker-entrypoint.sh, в котором происходит замена переменных с логином/паролем для аутентификации в Elasticsearch на их фактические значения. А переменные в контейнер пробрасываются благодаря описанию их в docker-compose.yml файле, который читает значения этих переменных из своего .env-файла
|
1 2 3 |
environment: CURATOR_USERNAME: ${CURATOR_USERNAME} CURATOR_PASSWORD: ${CURATOR_PASSWORD} |
Во втором файле, который используется curator-ом указываются действия, которые необходимо выполнить над индексами
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
1: action: delete_indices description: >- Delete indices older than 14 days (based on index name) Ignore the error if the filter does not result in an actionable list of indices options: ignore_empty_list: True disable_action: False filters: - filtertype: pattern kind: prefix value: '^(nginx-*|php-fpm-*|filebeat-*).*' - filtertype: age source: name direction: older timestring: '%Y.%m.%d' unit: days unit_count: 14 |
В action 1 выполняется удаление всех индексов, попадающих под указанный шаблон и которые были изменены более 14 дней назад
Т.е. логи nginx,php-fpm,mysql(они хранятся в индексе filebeat) храним только за последнии 14 дней
В action 2 выполняется удаление всех индексов, попадающих под указанный шаблон и которые были изменены более 30 дней назад
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
2: action: delete_indices description: >- Delete indices older than 30 days (based on index name) Ignore the error if the filter does not result in an actionable list of indices options: ignore_empty_list: True disable_action: False filters: - filtertype: pattern kind: prefix value: '^(system-*|secure-*|bash-history-*).*' - filtertype: age source: name direction: older timestring: '%Y.%m.%d' unit: days unit_count: 30 |
Т.е. системные логи, логи безопасности и логи с консольными командами храним только за последние 30 дней
Рассмотрим конфигурацию сервиса Cerebro
Подобно сервису Curator, у сервиса Cerebro также
При создании контейнера будет выполнен скрипт docker-entrypoint.sh, в котором происходит замена переменных(username/password) с логином/паролем для аутентификации в Elasticsearch на их фактические значения, которые будут находиться в конфигурационном файле application.conf
Также в этом конфигурационном файле настраивается подключение к Elasticsearch
|
1 2 3 4 5 6 7 8 9 10 |
hosts = [ { host = "http://elasticsearch:9200" name = "My Elasticsearch" auth = { username = "CEREBRO_USERNAME" password = "CEREBRO_PASSWORD" } } ] |
5.Создание пользователя fluentd с необходимыми привиллегиями в Elastcisearch, который будет использоваться в Fluentd/Filebeat-агентах для аутентификации/авторизации в Elasticsearch
1.Создание роли с именем fluentd для пользователя fluentd, с которым fluentd-агенты будут авторизовываться в Elasticsearch
|
1 2 3 4 5 6 |
Kibana->Management->Security->Role->Create role Role name: fluentd Elasticsearch-> Cluster privilleges->monitor Если необходима поддержка filebeat, тогда добавляем также следующие кластерные привиллегии manage_pipeline, manage_ingest_pipelines, manage_ilm, manage_index_templates |
|
1 2 3 |
Run as Privileges->оставляем пустым Index privileges->nginx-error-*, php-fpm-*, system-*, nginx-access*,filebeat-*,secure-*,bash_history-* Privilleges->все кроме All, delete, delete_index |
В поле Index privileges добавляем все индексы, в которые будут записывать fluentd/filebeat-агенты
(filebeat записывает все свои логии(включая логи MySQL) в один индекс с именем, которое попадает под паттерн filebeat-*
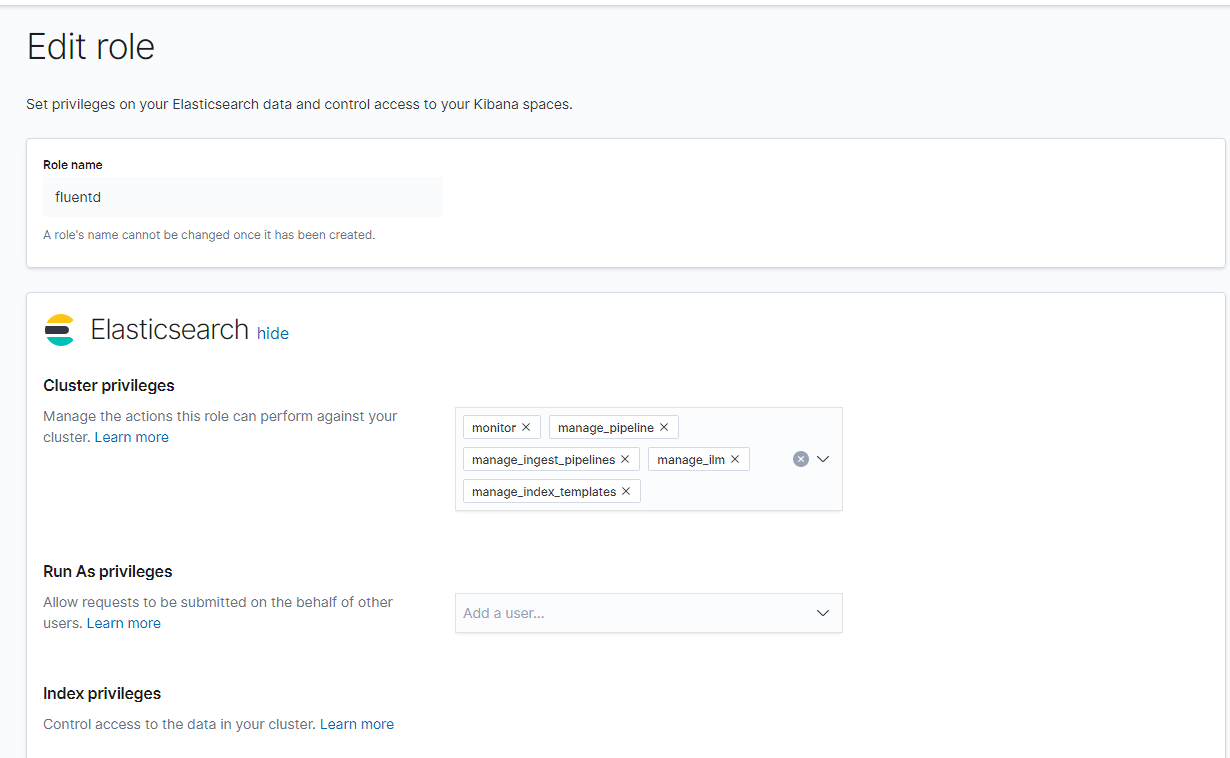
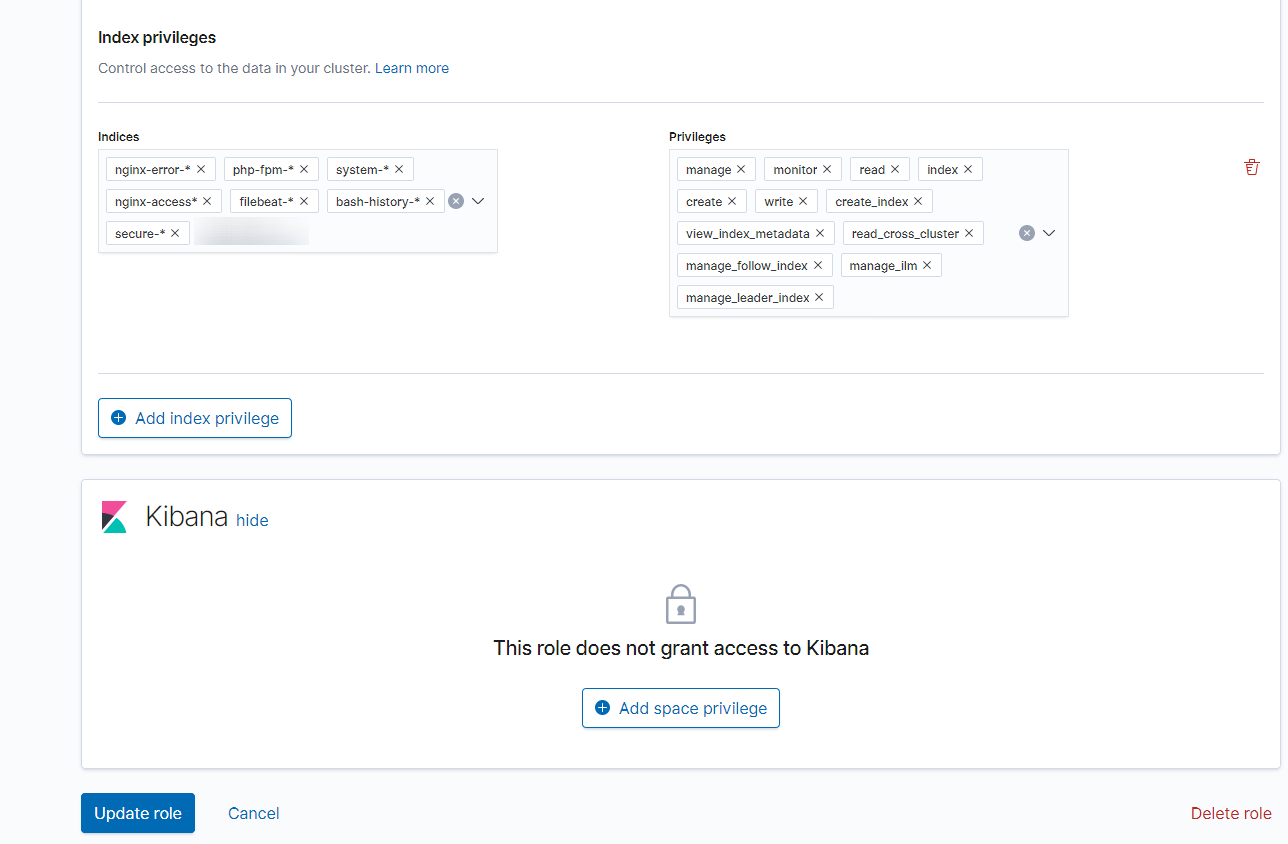
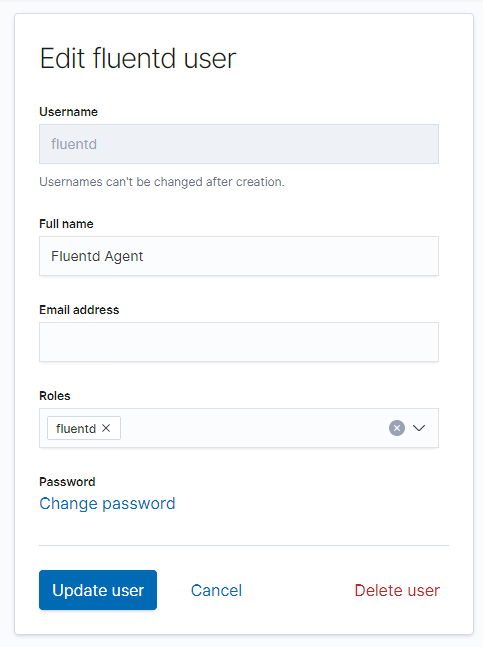
2.Создание пользователя fluentd, с которым fluentd-агенты будут аутентифицироваться и авторизовываться в Elasticsearch
|
1 2 3 4 5 6 |
Kibana->Management->Security->User->Create user Username: fluentd Password: mypassword Confirm password: mypassword Full name: Fluentd Agent Roles: fluentd |
 Опубликовано в рубрике
Опубликовано в рубрике  Метки:
Метки: